Aplikace pro podporu auditu datové kvality
[1.2.2012] D. PejčochAbstrakt
Článek shrnuje současné přístupy k auditu datové kvality, přičemž navazuje na postupy mapování vlastností dat a jejich důsledků pomocí kauzálních map publikované v (Pejčoch, 2011). Po stručném seznámení s typickou funkcionalitou dostupnou v rámci obecných nástrojů pro počítačovou podporu auditu (CAAT) a relevantní funkcionalitou obsaženou v nástrojích pro řízení datové kvality představuje aplikaci CADAQUES vyvíjenou autorem této práce.
Úvod
V příspěvku (Pejčoch, 2011) prezentovaném v rámci minulého ročníku Dne doktorandů byl naznačen přístup dávající do souvislosti úroveň vlastností jednotlivých atributů s jejich užitím a náklady plynoucími pro toto užití z naměřené úrovně vlastností. Výsledkem byla čtyřrozměrná OLAP kostka, která se následně stala zdrojem pro generování kauzalit, které demonstrovaly vztah vlastností dat co by metriky výkonnosti řízení dat do metrik výkonnosti řízení ostatních oblastí informatiky. Kauzality bylo možné vizualizovat pomocí kauzálních map a charakterizovat pomocí pravidel. V závěru citované práce bylo poněkud ambiciózně konstatováno, že uvedený přístup představuje návod pro realizaci auditu datové kvality. S odstupem času bych toto tvrzení přeformuloval tak, že uvedený přístup představuje základ pro postup realizace auditu datové kvality. V rámci této práce bych rád na dosud publikované závěry navázal a poskytl popis konkrétního návrhu aplikace pro podporu auditu datové kvality vycházející z těchto závěrů. Tato aplikace postupně vzniká na stránkách dqassessment.com. Její vybrané komponenty by mimo jiné měly později posloužit pro účely výuky v rámci mnou přednášeného předmětu 4IZ562 – Řízení datové kvality.
Připomeňme, že ve zmiňovaném příspěvku (Pejčoch, 2011) jsem vymezil na základě kompilace přístupů z více zdrojů celkem čtyři dimenze vlastností dat: (1) Endogenní vlastnosti, zahrnující důvěryhodnost, unikátnost, sémantickou a syntaktickou správnost, (2) Časovou dimenzi zahrnující aktuálnost, včasnost, volatilitu a časovou synchronizaci, (3) Kontextuální dimenzi, zahrnující konzistentnost vůči ostatním zdrojům a atributům, úplnost, pokrytí všech potenciálních hodnot a konečně (4) Dimenzi užití zahrnující vlastnosti jako je dostupnost, srozumitelnost, interoperabilita a bezpečnost přístupu. Dodatečně jsem tyto čtyři dimenze rozšířil ještě o dimenzi pátou, Ekonomickou dimenzi, reflektující (1) náklady na pořízení a aktualizaci datových zdrojů, (2) náklady na uložení, sdílení, distribuci, zálohování a archivaci a v neposlední řadě (3) náklady na ochranu dat.
Již uvedená práce (Pejčoch, 2011) naznačovala určité závislosti mezi jednotlivými vlastnostmi dat. Tyto kauzality měly však spíše povahu konstatování, že ke stanovení některých vlastností (zejména z časové dimenze) je nutné stanovit vlastnosti jiné. Na základě dalšího zkoumání jsem objevil i jiné, zajímavější kauzality, např. určité trade-off mezi vlastností „dostupnost“ a „bezpečnost přístupu“, či postupné promítání vlastností „spolehlivost“ a „úplnost“ do úrovně vlastnosti „důvěryhodnost“.
V uvedené práci (Pejčoch, 2011) jsem pouze konstatoval, že v rámci kauzalit figurují nějakým způsobem náklady plynoucí z úrovně vlastností daného atributu pro konkrétní užití. Na tomto místě bych rád na toto konstatování navázal a na základě přístupů publikovaných Loshinem (2011) a Englishem (1999) doplněných o své vlastní kategorie vymezil kompletní klasifikaci nákladů na nekvalitní data.
Audit datové kvality (Data Quality Assessment) představuje zpravidla první fázi implementace opatření pro zvýšení kvality dat / informací. Dosavadní přístupy se vesměs shodují, že kromě zjištění aktuálního stavu vlastností dat by měl obsahovat též analýzu užití (stávajícího i potenciálního) jednotlivých datových atributů a zjišťování příčin nekvalitních dat pomocí Root-Cause analýzy.
Podle Lee a kol. (2006) jej lze realizovat pomocí následujících technik: (1) kvalitativní šetření o datové kvalitě, (2) aplikace kvantitativních metrik, (3) analýza integrity dat podle TDQM (Total Data Quality Management). V praxi se podle Lee a kol. (2006) uplatňují tyto přístupy:
- Komparativní přístup, tj. srovnání výsledků subjektivního a objektivního assessmentu, zjištění příčin rozdílného vnímání a vzniku nekvalitních dat, návrh nápravných opatření;
- Subjektivní šetření hodnocení kvality dat, důležitosti vlastností, procesů, programů a nástrojů, jehož výsledky jsou často porovnávány v rámci benchmarkingu na globální úrovni nebo na úrovni hodnocení různými rolemi respondentů;
- Data Integrity Assessment, v rámci něhož je nejprve definováno, co znamená datová kvalita z pohledu dat a jejich kontextu (výstupem jsou integritní pravidla pro data) a následně je provedeno porovnání skutečného stavu s nadefinovanými pravidly, na které navazuje analýza kauzálních příčin narušení pravidel a plán nápravy nebo redefinice pravidel (v případě, že se ukážou jako chybná).
V rámci metodiky TQdM (Total Quality data Management) celosvětově uznávaného guru v oblasti datové a informační kvality Larry Englishe (1999) lze identifikovat kroky, které odpovídají auditu datové kvality. Jedná se o první tři fáze uvedené metodiky: (1) assessment definice dat a kvality informační architektury, (2) assessment informační kvality a (3) měření nákladů na nekvalitu.
V rámci prvního kroku uvažuje English tyto konkrétní kroky: (1) identifikaci metrik kvality definice dat, (2) identifikaci podstatných skupin informací k hodnocení, (3) identifikaci kategorií zainteresovaných subjektů pro vybrané skupiny informací (producenti, znalostní pracovníci, externí zákazníci, ...), (4) technický assessment kvality definice pro zjištění shody s datovými standardy a směrnicemi, (5) assessment kvality informační architektury a návrhu databází, (6) měření zákaznické spokojenosti s definicí.
V rámci druhého kroku uvažuje tyto činnosti: (1) potvrzení nebo definice skupin informací k hodnocení, (2) definice charakteristik, které budou měřeny, (3) definice vztahu informační hodnoty a nákladů pro jednotlivé skupiny informací, (4) identifikace zdrojů a procesů, které budou měřeny, (5) identifikaci zdrojů dat proti nimž je měřena správnost dat, (6) náhodný výběr dat pro assessment, (7) měření provedené na vzorku dat, (8) interpretaci zjištění a prezentaci / reporting úrovně informační kvality.
V rámci třetího kroku uvažuje: (1) nalezení metrik výkonnosti byznysu, (2) analýzu nákladů na informace, (3) odvození skupin nákladů pocházejících z chybějících a nekvalitních dat a kalkulaci měřitelných nákladů v důsledku selhání procesů, (4) identifikaci segmentů klientů, (5) výpočet životní hodnoty klienta a (6) kalkulace hodnoty informací jako dopadu do hodnoty klienta prostřednictvím nákladů na ztracené a propásnuté příležitosti.
McGilvray (2008) publikovala alternativní metodiku zvyšování kvality dat pod názvem „The Ten Steps Process“. Auditu datové kvality odpovídají kroky (1) definice byznys potřeb a přístupu, (2) analýza informačního prostředí, (3) data quality assessment založený na oskórování jednotlivých vlastností dat a (4) hodnocení byznys dopadu naměřených úrovní vlastností dat.
Přizpůsobením uvedených metodik jsem vytvořil postup, jehož kroky aktuálně převádím do konkrétní podoby aplikace. Metodiku auditu, stejně jako vznikající aplikaci, jsem pracovně nazval CADAQUES (Complex Audit of Data Quality in Enterprise Systems). Kombinuje v sobě kvalitativní a kvantitativní assessment uvažovaný Lee a kol. (2006) a modelování dopadu do skupin nákladů uvažovaných Englishem (1999) a McGilvray (2008).
Aplikace pro podporu auditu
Jak uvádí Svatá (2011), aplikace pro podporu auditu (CAAT – Computer-Assisted Audit Techniques) mohou výrazně zefektivnit práci auditora. Vzhledem k vysokému objemu dat, který je nutné zanalyzovat v rámci auditu informačních systémů, stává se dle mého názoru využití automatizovaných aplikací dokonce věcí nezbytnou. ISACA (2008) člení CAAT do pěti skupin: (1) obecný auditní software, (2) customizované dotazy nebo skripty, (3) utility, (4) software pro monitoring a mapping, a konečně (5) auditní expertní systémy.
Hamřík (2008) uvádí alternativní členění technik auditu s využitím CAAT: (1) GAS (Global Audit Software; obecné auditní systémy), (2) CAS (Custom Audit Software) vytvořené speciálně pro použití u konkrétního klienta, (3) paralelní simulace, tj. počítačová simulace imitující běžné fungování testovaných klientských programů a (4) integrovaná testovací zařízení, kdy auditor vkládá testovací data vedle aktuálních dat v běžně používaných aplikacích. Podobné členění technik auditování pomocí počítače uvažuje též Svatá (2011) a rozlišuje: (1) techniku testovacích dat, kdy se data zpracují na stejném systému jako živá data, (2) paralelní simulaci, kdy jsou stejná data zpracována systémem se stejnou funkcionalitou, (3) tzv. Integrated Test Facilities (pozn. autora: zřejmě lze přeložit jako integrovaná testovací zařízení), kdy se testovací data zpracovávají souběžně s „živými“ daty a (4) zabudovaný auditní modul, kdy jsou nastavovány různé reporty a logy monitorující průběh zpracování živých dat.
Funkcionalita dostupná v rámci nástrojů pro podporu auditu
Computer Assisted Audit Group (2009) uvádí následující specifické funkce díky níž se CAAT ukazují jako užitečné: (1) vytváření vzorků dat, (2) řízení souborů (slučování, porovnávání, řízení, oddělování) a (3) generování reportů. Na jiném místě dokumentu CAAG (2009) upřesňuje, že pod vytvářením vzorků dat rozumí stratifikovaný výběr. Tato forma výběru, uvažuje nejprve výběr části pozorování (tzv. strata), o níž se domníváme, že je více homogenní než celý základní soubor a teprve poté realizován náhodný výběr v rámci strat.
Sayana (2003) uvádí jako typickou funkcionalitu obecných auditních systémů extrakci dat z obecně používaných datových formátů a většiny databázových systémů, přičemž uvažuje přímé napojení CAAT na produkční data. Aplikace by podle něj rovněž měla umožňovat vytváření dotazů nad daty, statistickou analýzu dat, vytváření vzorků dat, horizontální spojování dat z různých zdrojů a identifikovat chybějící data v rámci řady. Svatá (2011) k této skupině CAAT ještě uvádí další příklady funkcionality: (1) identifikace zdvojených dat a (2) testování správného výpočtu časové struktury. Podobné funkce má podle Svaté (2011) poskytovat i druhá skupina aplikací, tj. customizované výběry a skripty. Třetí skupinu aplikací charakterizuje tentýž zdroj jako, SW utility „pro prověřování provozu systémů, testování, analýzu systémů, analýzu čerpání zdrojů, atd.“ Další skupina nástrojů, tzv. „Mapující a monitorující aplikační software“, podle téhož zdroje slouží k dokumentaci logiky, cest, podmínek kontrol a posloupnosti operací.
Poslední skupina nástrojů uvažovaná Svatou (2011), auditní expertní systémy, je z pohledu této práce nejzajímavější, neboť konkrétní řešení popsané dále spadá právě do této kategorie. Podle Feigenbauma (1979) je expertní systém: „inteligentní počítačový program, který užívá znalosti a inferenční procedury k řešení problémů, které jsou natolik obtížné, že pro své řešení vyžadují významnou lidskou expertízu“. Alternativní definice poskytuje Gosman (1990), když považuje expertní systém za: „počítačový program simulující rozhodovací činnost lidského experta při řešení složitých úloh a využívající vhodně zakódovaných speciálních znalostí převzatých od experta s cílem dosáhnout ve zvolené problémové oblasti kvality rozhodování na úrovni experta“.
Cannon (2008) uvádí následující členění SW nástrojů a technik obsažených v CAAT: (1) nástroje pro hodnocení slabin nastavení systému, (2) analýzu síťového provozu a protokolů s využitím analyzátorů packetů, (3) mapovací a monitorovací nástroje, (4) software pro testování konfigurace specifických aplikací, (5) software pro kalkulaci počtu licencí napříč sítí a (6) testování shody hesel (pozn. autora: s interními standardy) u uživatelských účtů.
V případě kontinuálního online auditu rozlišuje Cannon (2008) tyto techniky: (1) online monitory událostí procházející logy a upozornění, (2) vestavné „pojistky“ pro audit programů označující transakce, které je vhodné přezkoumat, (3) kontinuální a namátková simulace (CIS) založené na auditu transakcí splňujících určitá předdefinovaná kritéria, (4) snímkování dat a sestavení sekvence zachycených snímků do souvislého souboru kroků v rámci transakce, (5) vestavné auditní moduly (EAM) zpracovávající fiktivní transakce společně s těmi pravými a (6) SCARF/EAM, tj. auditní programy na úrovni systému monitorující vestavné auditní moduly uvnitř aplikačního software.
Vhodná funkcionalita pro nástroje auditu datové kvality
Funkcionalita pro posouzení úrovně aktuální kvality dat je zpravidla v určité míře součástí každého nástroje pro řízení kvality dat. Jedná se hlavně o komponenty, které souvisejí s profilací dat a monitoringem datové kvality. Není snad jediné schéma procesu řízení datové kvality, ve kterém by tyto dvě komponenty chyběly. V prvním případě se jedná o soubor funkcí pro základní popisné statistiky (medián, modus, maximum, minimum, frekvenční analýza), analýza syntaktických vzorů, porovnání dat s metadaty, ověření referenční integrity, zatímco v druhém případě se jedná převáženě o sledování výstupů nadefinovaných byznys pravidel. Výstupy monitoringu mimo jiné ukáží, jak účinné jsou současně platné kontroly a slouží jako podklad pro kalkulaci ROI programu řízení datové kvality. Pro účely permanentního sledování je často řešení pro řízení datové kvality vybaveno komponentou reagující na konkrétní události spuštěním komponenty jiné, záznamem do logu, anebo inicializací tzv. upozornění. V rámci komponenty pro monitoring je též často k dispozici funkcionalita pro zobrazení přehledů a sledování trendu.
Pro audit datové kvality lze úspěšně použít i další komponenty sloužící pro verifikaci proti externím datovým zdrojům jako je např. ověřování adres proti územně identifikačnímu registru UIR-ADR, číselníkům MV ČR, komerčním kompilacím více registrů jako je např. Credit Info a Registru ekonomických subjektů (v tomto případě je ale nutné postupovat obezřetně, neboť se nejedná o datově „čistý“ zdroj). Funkcionalita z této oblasti by měla umožňovat jak přesný join na základě jedinečného klíče, tak přibližný join, realizovaný optimálně (zejména z výkonnostních důvodů) pomocí porovnávacích kódů.
Pro účely posouzení aktuálního stavu duplicit s cílem stanovit kvantitativní metriky unikátnosti je vhodné též začlenit funkcionalitu pro shlukování záznamů se shodnými porovnávacími kódy vygenerovanými na základě apriorních znalostí o sémantickém typu daného atributu a zadané míry požadované shody. Podrobně jsem se problematice generování porovnávacích kódů věnoval např. v jednom ze svých starších příspěvků na Den doktorandů (Pejčoch, 2009).
Zejména pro účely generování porovnávacích kódů je naprosto nezbytnou součástí řešení pro datovou kvalitu tzv.Quality Knowledge Base (QKB). Obsahuje zpravidla součásti specifické pro jednotlivá jazyková / národní prostředí, jako jsou na jednotlivé sémantické datové typy navěšené gramatiky (syntaktická pravidla s odhadem pravděpodobnosti jejich výskytu jako váhou), fonetické knihovny, obsahující pravidla pro záměnu různých hlásek (např. zdvojených samohlásek) a snažící se eliminovat překlepy u shodně znějících slov, slovníky, standardizační schémata, knihovny regulárních výrazů a tabulky přípustných znaků. Všechny zmiňované komponenty slouží při auditu datové kvality jednak pro účinné generování porovnávacích kódů a jednak pro validační pravidla sloužící pro stanovení míry syntaktické a sémantické správnosti. Pro účely monitoringu datové kvality znalostní báze též obsahuje nadefinovaná byznys pravidla.
V úvodu této práce jsem vyjádřil svůj záměr poskytnout úplnou klasifikaci nákladů plynoucích z nekvalitních dat. Jako základ mi posloužilo členění uvedené Loshinem (2011) a Englishem (1999). David Loshin člení náklady do následujících kategorií: (1) Finanční dopad (přímé operační náklady, režijní náklady, dodatečné poplatky, změny v cash-flow, dopad do odpisů a úniku peněž z firmy např. v důsledku fraudů), (2) dopad do spokojenosti spotřebitele a jeho očekávaného tržního chování, (3) dopad do rizika a compliance a konečně (4) dopad do produktivity firmy. Larry English uvažuje následující alternativní členění: (1) náklady plynoucí přímo z nekvalitních informací, (2) náklady na assessment nebo kontrolu, (3) náklady spojené se zlepšováním procesů a předcházením defektům. Pokud tyto dvě klasifikace podrobíme hlubšímu zkoumání, zjistíme, že se v podstatě doplňují a představují dvě dimenze pohledů na náklady, které je vhodné uvažovat současně. Larry English v podstatě pouze dále člení náklady, které D. Loshin označuje za „finanční dopad“. Výsledný přehled doplněný o další dle mého názoru oprávněné podskupiny nákladů na znázorňuje tabulka č. 1.
| Kategorie | Podkategorie |
|---|---|
| FI: Finanční dopad |
|
| CS: Dopad do spokojenosti klienta |
|
| RC: Dopad do rizika a compliance |
|
| PM: Dopad do produktivity firmy |
|
Zkratky uvedené před názvy přestavují jazykově nezávislé kódy příslušných číselníků použitých v aplikaci CADAQUES. Stejně tak jako v případě vlastností dat, je zde zřejmé, že některé kategorie nákladů spolu budou kauzálně souviset. Např. RC2: Soudní žaloby budou mít zřejmě též zprostředkovaně dopad do FI1: Přímé náklady, stejně tak jako do CS2: Odchod klienta.
V rámci shromažďování požadavků na funkcionalitu nástroje pro audit datové kvality jsem identifikoval potřebu existence tzv. Kanonického datového modelu jako součásti znalostí báze. Pojem Kanonický datový model (též Společný datový model) pochází z oblasti datové integrace. Význam slova kanonický lze v českém jazyce chápat jako „odvozený, vztahující se ke kánonu (tedy měřítku, pravidlu, souboru zásad, představě o ideálních proporcích). V matematice představuje kanonický tvar formu, ve které může být objekt jednoznačně prezentován. V oblasti datové integrace jej Štumpf a Džmuráň (2008) zmiňují jako model na konkrétní aplikaci nezávislý. Pro účely znalostní báze řešení pro audit datové kvality uvažuji Kanonický datový model jako referenční sadu atributů nazvanou jednotnými syntaktickými pravidly, na které se odkazují další části znalostní báze, např. byznys pravidla, syntaktická pravidla, knihovny regulárních výrazů, ale i znalosti naakumulované v rámci předchozích auditů (např. formy užití atributu pro různé role, související typy a výše nákladů, sada vlastností dat, které je vhodné pro daný sémantický datový typ sledovat, apod.). Na jednotlivé atributy Kanonického datového modelu jsou v průběhu mého pojetí auditu namapovány skutečné atributy, zařazené do assessmentu.
Štumpf a Drmuráň (2008) odkazují na řadu existujících Kanonických modelů pro různé vertikály. Pro oblast pojišťovnictví je to ACORD (Association for Cooperative Operations Research and Development), pro telekomunikace SID, pro oblast veřejných služeb CIM (Common Information Model), pro energetiku PPDM, resp. MMDM, pro oblast výroby a dodavatelsko-odběratelské řetězce OAGIS (Open Application Group Integration Specification), pro zdravotnictví HL7 (Health Level Seven International) a HIPAA, pro oblast prodeje ARTS (The Association for Retail Technology Standards) a konečně pro kapitálové trhy FPML či SWIFT.
CADAQUES, aplikace pro podporu auditu datové kvality
Aplikace CADAQUES představuje konkrétní realizaci principů popsaných výše. Aplikace je programována v jazycích PHP, JavaScript a Perl. Jako databázovou platformu používá primárně MySQL. Postupně jsou do ní přidávány též konektory na jiné RDBMS. Aktuálně je hotový konektor na Informix a MSSQL, připravovány jsou konektory na Firebird, DB2, PostgreSQL a Oracle 11g. Data lze do aplikace importovat též prostřednictvím txt souborů s oddělovačem. Standardním úložištěm pro data auditu, vstupní data a znalostní bázi (QKB) je MySQL. V současné době není možná online integrace voláním webových služeb aplikací třetích stran. QKB obsahuje kromě výše zmíněných gramatik, knihoven a pravidel též následující komponenty specifické pro audit datové kvality:
- Kanonický datový model,
- Výběr typických atributů Kanonického modelu pro vybranou vertikálu,
- Přiřazení typických rolí uživatelů pro danou vertikálu,
- Přiřazení typického užití dat k rolím,
- Přiřazení vlastností dat typicky sledovaných pro jednotlivé atributy Kanonického modelu v rámci příslušného užití,
- Přiřazení typických druhů nákladů a jejich obvyklé „fuzzy“ úrovně na jednotlivé úrovně vlastností dílčích atributů,
- Pravidla pro fuzzifikaci pro jednotlivé druhy nákladů v rámci užití,
- Pravidla pro fuzzifikaci pro jednotlivé vlastnosti dat podle atributů Kanonického modelu,
- Sady pravidel vyjadřující apriorní znalosti o kauzalitách mezi atributy Kanonického modelu, úrovní vlastností dat a souvisejícími náklady pro jednotlivé vertikály,
- Sadu otázek pro kvalitativní šetření subjektivních vlastností dat.
Jak již vyplynulo z použitých technologií, interakce s uživatelem probíhá pomocí webové aplikace. V rámci ní je možné administrovat jednotlivé části znalostní báze, na „dashboardu“ sledovat aktuální stav jednotlivých auditů, v rámci jednotlivých auditů sledovat jejich výsledky, generovat zprávu auditora, zakládat nové audity, řídit běh již vytvořených auditů. Postup přípravy auditu zahrnuje podle metodiky CADAQUES následující kroky:
- Založení metadat auditu (výběr partnera, výběr vertikály, vložení popisných údajů nutných pro vygenerování zprávy auditora na závěr auditu),
- Definici zdrojových systémů,
- Přiřazení rolí jednotlivým respondentům na základě QKB a jejich následnou úpravu,
- Přiřazení užití jednotlivým rolím na základě QKB a jejich následnou úpravu,
- Výběr relevantních domén z Kanonického datového modelu,
- Přiřazení nákladů z QKB a jejich následnou úpravu,
- Prioritizaci,
- Přiřazení reálných dat ke kanonickému modelu,
- Vygenerování dotazníku pro kvalitativní šetření.
Uživatel je provázen jednotlivými kroky zakládání auditu formou wizardu. V rámci jednotlivých kroků je možné nahrát znalosti z QKB, ručně vkládat / editovat údaje nebo je nahrát z externího textového souboru s oddělovačem. K jednotlivým fázím je možný dodatečný návrat kliknutím na záložku příslušného kroku.
Vlastní spuštění je možné provést z přehledu vytvořených auditů. Po spuštění jsou odemknuty pohledy na dotazníky kvalitativního šetření a jednotlivým respondentům jsou na e-mail zaslány pozvánky k jejich vyplnění. Audit kvantitativních vlastností dat extrahovatelných z dat je vhodné spustit vzhledem k zátěži separátně. Načasování běhu jednotlivých komponent lze při instalaci na operačním systému Linux administrovat přímo z rozhraní aplikace. Při spuštění auditu je též dogenerován zbytek tabulek představujících OLAP kostku výsledků auditu v tzv. star schématu. Prvky jejích dimenzí byly nadefinovány během průchodu wizardem při zakládání auditu.
Porovnávací kódy jsou v CADAQUES vytvářeny podle následujícího postupu: (1) převedení všech znaků na kapitálky, (2) odstranění diakritiky, (3) aplikace fonetických pravidel, (4) tokenizace, (5) rozpoznání významu jednotlivých tokenů, (6) aplikace standardizačních schémat, (7) vytvoření vlastního porovnávacího kódu.
Největší slabinou CADAQUES v současné verzi je nízká podpora pro statistickou analýzu v rámci průběhu auditu. Je sice možné zvolit způsob náhodného výběru dat, součástí automatického vyhodnocování kvantitativních vlastností je výpočet základních popisných statistik, ale pokud nepovažujeme za statistický nástroj integrovaný formulář pro vkládání SQL (Structure Query Language) příkazů, je v této oblasti funkcionalita zcela nesrovnatelná s jinými nástroji.
Lee a kol. (2006) představuje značně inspirativní materiál pro definici konkrétních otázek kladených v rámci kvalitativního šetření. Publikace obsahuje řadu otisků obrazovek z konkrétního realizovaného assessmentu. Ze zkušenosti doporučuje zařazení i takových otázek, které směřují k objektivním vlastnostem dat, jejichž úroveň je zjišťována přímo analýzou dat. Současným zařazením do kvalitativního šetření je možné porovnat vnímání těchto vlastností uživateli s realitou. I v tomto směru jsem se inspiroval a v rámci zobrazení výsledků auditu je možné u vybraných vlastností jejich subjektivní i objektivní hodnocení porovnat.
Nutno poznamenat, že formulář metadat auditu svou strukturou odpovídá formálním požadavkům §20 zák. 93/2009 Sb. o auditorech (Česko, 2009), standardu S7-Reporting a návodu G20-Reporing publikovanými ISACA (Information Systems Audit and Control Association) v (ISACA, 2003) a (ISACA, 2004). Důvodem je zajištění možnosti snadného automatického vygenerování zprávy v požadované struktuře v závěru auditu.
Jak bylo již naznačeno v (Pejčoch, 2011), pro další práci s informacemi zjištěnými v rámci auditu je vhodné spojité proměnné fuzzifikovat. Experimentální fuzzifikace nad vlastnostmi z reálného auditu potvrdila domněnku, že ne ke všem vlastnostem je možné v rámci fuzzifikace přistupovat stejně napříč všemi atributy. V některých případech, např. při srovnání úplnosti u rodného čísla a čísla mobilního telefonu, nejen že prahová hodnota pro fuzzy množinu leží jinde z toho důvodu, že zarážející v případě rodného čísla je již výskyt chybějících hodnot nižší než o10 %, než je potenciální pokrytí (reálný výskyt chybějících hodnot je v případě rezidentů cca 0,5 %), zatímco v případě mobilního telefonu 10% deficit vlastnosti „úplnost“ není nic překvapivého. Uvedené atributy jsou rovněž dobrým příkladem pro demonstraci možné míry potenciálního pokrytí. V případě rodného čísla je mezi fyzickými osobami s trvalým bydlištěm na území ČR maximální pokrytí 100%. V případě čísla mobilního telefonu se pohybuje v průměru někde na hranici 90 % a se zvyšující věkovou skupinou se též zvyšuje četnost jedinců, kteří mobilní telefon nevlastní. Ještě nižší potenciální pokrytí bychom byli nuceni uvažovat v případě e-mailové adresy. Uvedené skutečnosti mě vedly k tomu, abych do QKB též ke každému sémantickému typu přiřadil apriorní znalost o použitém způsobu fuzzifikace. Obecné schéma použité pro vlastnosti dat je znázorněno na Obrázku č. 2. Jeho aplikace na různé atributy se liší pouze reálnou výší potenciálního pokrytí vyjádřenou hodnotou max a výší označenou jako „Hranice užití“ odpovídající úrovni vlastnosti, při níž již není myslitelné daný atribut využívat pro žádné zamýšlené užití.
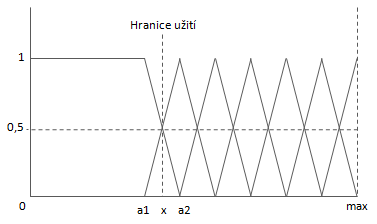
Jednotlivým množinám odpovídá následující popis pojmy přirozeného jazyka: Vynikající, Velmi dobrá, Dobrá, Spíše horší, Špatná, Velmi špatná, Kritická. V případě aplikace na fuzzifikaci finančních nákladů se tvar použitých fuzzy množin liší pouze v tom směru, že schéma je symetrické podle mediánu. Platí tedy, že stejně tak jako když při dosažení určité dolní hranice je příslušnost ke kvalitativně „nejhorší“ množině rovna jedné pro všechna x nižší, než je prahová hodnota (viz Obrázek č. 2), i pro taková x, která jsou vyšší než prahová hodnota na opačném konci spektra, je již rovna jedné příslušnost k fuzzy množině kvalitativně „nejlepší“. Jednotlivým množinám odpovídá následující popis pojmy přirozeného jazyka: Velmi vysoké, Vysoké, Spíše vyšší, Střední, Spíše nižší, Nízké, Velmi nízké.
Apriorní náklady v QKB jsou chápány jako náklady jednotkové, které lze při kalkulaci celkových nákladů vážit mírou příslušné vlastnosti jako odhadem pravděpodobnosti výskytu a počtem jednotek, u nichž k daným jednotkovým nákladům dojde. V řadě případů je však nutné uvažovat jiný přístup, který vychází z principu existence KO kritérií pro výskyt nákladů v určité výši. V některých případech, např. u nedodržení compliance s určitou normou, nastávají náklady v konkrétní výši bez ohledu na skutečnost, jaká konkrétní úroveň dané vlastnosti dat byla reálně naměřená. Ve znalostní bázi je tato skupina nákladů označena příznakem.
Apriorní pravidla jsou v QKB uložena jako asociační pravidla ve struktuře definované čtyřmi na sebe navázanými tabulkami. Základ této struktury tvoří tabulka hypotéz. Obsahuje základní metadata hypotéz a jejich vazbu na příslušnou vertikálu.Ve vztahu N:1 je k tabulce hypotéz tabulka jednotlivých cedentů. Obsahuje označení typu cedentu (Antecedent, Succedent, Condition) a vazbu na jednotlivé dílčí cedenty uložené v další tabulce (k tabulce cedentů ve vztahu N: 1). Poslední prvek báze uložených pravidel tvoří tabulka jednotlivých literálů, která je ve vztahu N:1 k tabulce dílčích cedentů. Tabulky cedentů a dílčích cedentů obsahují informaci, zda jsou v rámci nich prvky nižší hierarchie uvažovány jako spojené konjunkcí či disjunkcí. Jelikož dílčí cedenty uvažuji jako jednotlivé atributy Kanonického modelu, odkazuje se tabulka dílčích cedentů přímo na primární klíč příslušné tabulky modelu.
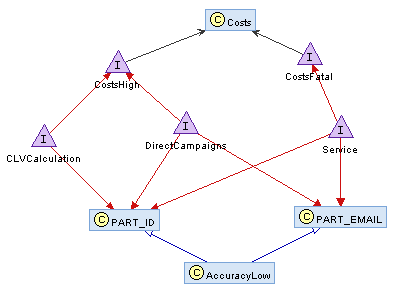
Výsledky auditu jsou v současné době pro vizualizaci vybírány na základě manuálního označení jednotlivých pravidel seřazených podle míry dopadu. Do budoucna plánuji jejich automatickou extrakci. Jelikož možnosti vizualizace kauzalit jsou v případě jazyka PHP poněkud omezené, rozhodl jsem se pro zobrazení výsledných pravidel použít externí aplikaci. Abych zajistil co největší míru abstrakce od konkrétní aplikace, CADAQUES umožňuje export výsledků auditu do formátů RDF (Resource Description Framework) a OWL (Web Ontology Language) V obou případech se jedná o aplikace jazyka XML (eXtensible Markup Language). OWL je založený na základních elementech RDF, ale poskytuje více pojmů pro popis vlastností a tříd. Pro uvedené formáty jsem též našel vhodnou aplikaci pro vizualizaci; v případě RDF např. RDF Gravity a v případě OWL nástroj Protégé (resp. jeho zásuvné moduly NavigOwl a OntoGraf). V obou případech se jedná o volně dostupnou aplikaci. Příklad vizualizace výsledků auditu ve formátu RDF pomocí nástroje RDF Gravity znázorňuje Obrázek č. 2.
Závěr
V rámci své výzkumné činnosti jsem se pokusil zkombinovat hlavní rysy stávajících přístupů pro audit datové kvality a na výsledném konceptu založit vlastní aplikaci spadající do kategorie (CAAT – Computer-Assisted Audit Techniques). V této snaze se cítím být stále ještě na začátku. Řada modulů aplikace je sice již v tuto chvíli hotova, ale mnoho funkcionality dostupné v rámci standardních nástrojů pro podporu auditu zbývá ještě vyvinout.
Jedním ze zamýšlených směrů dalšího rozvoje je přímá integrace nástroje pro vizualizaci výsledků do aplikace. S tím souvisí i experimentování s dalšími alternativními aplikacemi jazyka XML. Jako možná cesta se nabízí jazyk SWRL (Semantic Web Rule Language) nebo přímo jazyk RuleML (Rule Markup Language), ze kterého je SWRL odvozen. Další zamýšlenou oblastí rozvoje je již zmiňovaná automatická extrakce pravidel z výsledků auditu.
V současné době má začleňování apriorních znalostí z QKB převážně podobu možnosti importu pravidel z báze. Do budoucna uvažuji rozšíření těchto možností o funkcionalitu inteligentního agenta, který by v průběhu vytváření auditu „našeptával“ jak při daném kroku postupovat, přičemž by následná doporučení upravoval podle toho, zda se auditor rozhodl jeho předchozí rady poslechnout či vybral alternativní variantu.
Obecně zvažuji převedení aplikace do jiného programovacího jazyka. Vzhledem k množství volně dostupných potenciálně využitelných knihoven vytvořených v jazyku Java (např. knihovna Simmetrics pro míry podobnosti řetězců) vážně uvažuji o J2EE (Java 2 Enterprise Edition).
Poznámka: Tento článek byl původně publikován jako příspěvek na Den doktorandů, dne 14. února 2012.
Literatura
- COMPUTER ASSISTED AUDIT GROUP. A Guide to Computer Assisted Audit Techniques, In: Commonwealth of Massachusetts [online]. @2009[cit. 2012-01-20] Dostupné z: http://www.mass.gov/dor/docs/dor/publ/pdfs/caat.pdf
- ENGLISH, Larry P. Improving Data Warehouse and Business Information Quality: Methods for Reducing Costs and Increasing Profits. New York: Wiley & Sons, 1999. xxvi, 518 s. ISBN-10 0-471-25383-9.
- FEIGENBAUM, E. A. Themes and Case Studies of Knowledge Engineering. In Expert Systems in the Micro-Electronic Age. Edinburgh: University Press, 1979.
- CANNON, David, L. CISA Certified Information Systems Auditor Study Guide, Second Edition. Indianapolis: Wiley, 2008. ISBN 978-0-470-23152-4.
- GOSMAN, S., ET AL. Umělá inteligence a expertní systémy. Výběr informací z organizační a výpočetní techniky. Praha, 1990.
- HAMŘÍK, A., STRÁNSKÝ, M. Auditorská rizika a postupy vyplývajícíc z využití ICT v účetnictví. In: PWC [online]. 2008-06-04[cit. 2012-01-29]. Dostupné z: http://www.pwc.com/cz/cs/clanky-2008/auditorska-rizika-a-postupy-vyplyvajici-z-vyuziti-ict-v-ucetnictvi.jhtml
- ISACA. IT Audit and Assurance Guideline G20 Reporting. In: ISACA [online]. @2003, 2010[cit. 2012-01-22]. Dostupné z: http://www.isaca.org/Knowledge-Center/Standards/Documents/G20-Reporting-13Aug2010.pdf
- ISACA. IS Auditing Standard Reporting Document #S7. In: ISACA [online]. @2004[cit. 2012-01-22]. Dostupné z: http://www.isaca.org/Knowledge-Center/Standards/Documents/ Audit20Standards/S7ReportingStandardRevised2Mar05.pdf
- ISACA. IS Auditing Guideline G3 Use of Computer-Assisted Audit Techniques (CAATs). In: ISACA [online]. ©1998, 2008[cit. 2012-01-29]. Dostupné z: http://www.isaca.org/Knowledge-Center/Standards/Documents/G3-Use-of-CAATs-16Jan08.pdf
- LEE, Yang W., PIPINO, Leo L., FUNK, James D., WANG, Richard Y. Journey to Data Quality. The MIT Press, 2006. 240 s. ISBN-10 02-621-2287-1.
- LOSHIN, D. The Practitioner’s Guide to Data Quality Improvement. Burlington: Morgan Kaufmann as inprint of Elsevier, 2011. ISBN 978-0-12-373717-5.
- McGILVRAY, D. Executing Data Quality Projects: Ten Steps to Quality Data and Trusted Information. Morgan Kaufmann, 2008. xviii, 325 s. ISBN 978-0-12-374369-5.
- PEJČOCH, D. Vztah řízení dat k ostatním oblastem řízení informatiky. In: Sborník prací účastníků vědeckého semináře doktorského studia. Praha: Fakulta informatiky a statistiky VŠE, 2011. ISBN 978-80-245-1761-2.
- PEJČOCH, D. Benchmark přístupů k Fuzzy Match / Merge. In: Sborník prací účastníků vědeckého semináře doktorského studia. Praha: Fakulta informatiky a statistiky VŠE, 2009. ISBN 978-80-245-1524-3 .
- SAYANA, S. Anantha. Using CAATs to Support IS Audit. In: ISACA Journal [online]. ©2003[cit. 2012-01-28]. Dostupné na: http://www.isaca.org/Journal/Past-Issues/2003/Volume-1/Pages/Using-CAATS-to-Support-IS-Audit.aspx
- SVATÁ, V. Audit informačního systému. Příbram: Professional Publishing, 2011. ISBN 978-80-7431-034-8.
- ŠTUMPF, J., DŽMURÁŇ, M. Datová integrace prostřednictvím společného datového modelu. In: Proceedings of the 16th International Conference on Systems Integration 2008, Prague, Czech Republic, June 10 – 11. Praha: CSSI, 2008, ISBN 978-80-245-1373-7
- ČESKO. Zákon č.93 ze dne 26. března 2009 o auditorech a o změně některých zákonů (zákon o auditorech).. In: Sbírka zákonů České republiky. 2009, částka 30, s. 1166-1204. Dostupný také z: www.mvcr.cz/soubor/sb030-09-pdf. ISSN 1211-1244.