DOPAD NEKVALITNÍCH DAT DO METRIK VÝKONNOSTI PODNIKU
[1.11.2011] D. PejčochAbstrakt
Se stále rostoucím objemem zpracovávaných dat ve firmách se do popředí zájmu manažerů dostala problematika datové kvality a s ní otázka, jakou míru požadovaných vlastností mají data splňovat. Data však přes svůj bezesporný význam nejsou jediným klíčovým aktivem firmy. Rovněž tak otázka řízení dat není zcela oddělena od ostatních oblastí řízení. Tato práce usiluje o komplexní popis dopadu vlastností dat do nákladů a bilance firmy prostřednictvím užití dat. Při demonstraci těchto “kauzalit” vycházím z přístupu nazývaného Fuzzy Cognitive Maps.
Úvod
Se stále rostoucím objemem zpracovávaných dat ve firmách i státních organizacích narostl jejich význam co by nutného zdroje jak pro běžný provoz instituce, tak i pro analytické úlohy a reporting (souhrnně Business Intelligence). Mám-li špatná data (neúplná, chybná, roztroušená, … viz dále), nemohu očekávat, že je budu interpretovat správně a získám správné informace (jak pregnantně vyjadřuje již notoricky známé rčení „Garbage in, Garbage out“). Na jejich základě nemohu získat správné znalosti a na jejich základě vytvořím chybné vize. Tento vztah pregnantně vystihuje tzv. Hierarchie znalostí publikovaná např. prof. Zeleným v [10]. Přiřazením systémů, které s jednotlivými úrovněmi hierarchie pracují, můžeme zjistit, že data nejsou v rámci firmy osamocena. Jedná se o jedno z klíčových aktiv, které v případě svého využití ve firmě může poskytnout jednak přínosy (pokud splňuje vlastnosti, jaké jsou od něj očekávány), anebo značné ztráty (pokud tyto vlastnosti nemá). Má práce staví na hypotéze, že vztah mezi úrovní vlastností dat, užitím dat a náklady / přínosy plynoucími z tohoto užití lze znázornit pomocí kauzálních map. Na základě těchto kauzalit lze vytvořit simulační model, který bude ukazovat dopad různé úrovně vlastností dat do celkové bilance podniku. Předpokládám tedy, že není nutné a priori řídit vlastnosti všech datových atributů a současně předpokládám větší význam některých vlastností. Při modelování „kauzalit“ se opírám o koncept Fuzzy Cognitive Maps publikovaný např. ve sborníku [4].
Vlastnosti dat
Datová kvalita je často definovaná jako míra určitých požadovaných vlastností. Tyto vlastnosti jsou zpravidla vztahovány k užití dat. Např. J. M. Juran definuje pojem datová kvalita takto: „Data mají vysokou kvalitu, pokud tato odpovídá jejich zamýšlenému užití v provozu, rozhodování a plánování“. Řízení dat jako jedné z dimenzí řízení informatiky lze potom ztotožnit s řízením těchto požadovaných vlastností. Současně lze na tyto vlastnosti pohlížet jako na metriky výkonnosti řízení této dimenze.
Téma vlastností dat je i s dílčími pokusy o vytvoření metrik jejich naplnění poměrně obsáhle zpracováno např. v [1], [7] či [9] . V některých aspektech se tyto zdroje doplňují, některým prakticky totožným vlastnostem dávají pouze různé názvy. U jednotlivých autorů dochází i ke snaze o členění vlastností do skupin podle různých hledisek. Pro účely své práce jsem na základě syntézy uvedených zdrojů vytvořil vlastní klasifikaci vlastností dat, popsanou v tabulce č. 1.
Již na první pohled je zřejmé, že mezi některými vlastnostmi dat existují určité vztahy. Ke stanovení míry naplnění části vlastností je třeba stanovit míry jiných vlastností (např. včasnost lze stanovit pomocí životnosti a volatility). Kromě těchto triviálních vazeb lze vypozorovat i složitější kauzality. Např. pokud atribut obsahuje nesprávně chybějící hodnotu (tzn. hovoříme primárně o dopadu do míry úplnosti s ohledem na kontext), lze se domnívat, že dojde též k současnému dopadu do míry důvěryhodnosti vlivem poklesu uživatelské akceptovatelnosti tohoto atributu jako zdroje pro získání znalostí. K dopadu do úrovně obou vlastností však nemusí nutně dojít současně, tzn. pokles míry úplnosti zřejmě až dodatečně ovlivňuje důvěryhodnost tohoto atributu z pohledu jeho uživatelů.
Lze si též všimnout, že některé vlastnosti jsou spíše objektivního charakteru, tj. jsou snadno měřitelné a jak uvádí [8], nejsou závislé na úloze, v rámci níž jsou data používána (např. správnost nebo včasnost), zatímco jiné mohou být značně ovlivněny subjektivním názorem uživatele dat (subjektivní metriky, např. důvěryhodnost). Zatímco první uvedenou skupinu vlastností lze naměřit snadno přímo z dat, v druhém případě je pro stanovení vlastností nutné provést kvalitativní šetření mezi uživateli dat.
Využití dat ve firmě
Jak již zde bylo naznačeno, data jsou ve firmách používána k různým účelům, provozní činností počínaje, přes reporting, akviziční a retenční aktivity, využití v expertních systémech, až po systémy pro podporu rozhodování (Manažerské informační systémy, Systémy pro strategické rozhodování). Paleta využití je tedy značně široká. Neznamená to však, že všechna data, která podnik shromažďuje a spravuje za cenu nákladů na uložení / archivaci využívá současně pro všechny uvedené účely. Pro zefektivní řízení dat je proto vhodné mít k dispozici přehled užití jednotlivých atributů. Tento přehled nám nejlépe poskytne modifikace tzv. Bus-matrix obsahující na vertikále jednotlivé datové atributy popsané svými byznys názvy s uvedeným zdrojovým systémem.V horizontální dimenzi matice jsou potom uvedeny jednotlivé typy užití. Vlastní hodnoty matice potom mohou představovat buď prostý příznak užití daného atributu, anebo mohou mít i hlubší význam, např. celkové náklady / přínosy daného užití. Na úrovni jednotlivých řádků lze potom kvantifikovat celkové náklady na užití daného atributu, resp. jeho celkové přínosy. Na úrovni sloupců potom náklady / přínosy daného užití napříč všemi atributy. Tento přístup samozřejmě předpokládá, že je možné náklady / přínosy rozpadnout v granularitě matice. Nutno však podotknout, že v případě kalkulace celkových nákladů je navíc ještě nutné zakomponovat do výpočtu konstantní náklady na uložení dat, které jsou nezávislé na míře jejich užití.
Sumarizace nákladů / přínosů na úrovni jednotlivých řádků může poskytnout podklady pro jakousi formu prioritizace řízení jednotlivých atributů. Tento přístup do určité míry kopíruje postup publikovaný v [14]. Je třeba vzít též v patrnost, že při určení užití jednotlivých atributů je účelné rozlišovat jejich současné a potenciální užití. Pokud bychom opomenuli monetární potenciál dat, mohli bychom snadno zbrkle přiřadit nízkou prioritu skupině atributů, jejichž vlastnosti bychom v budoucnu napravovali jen velmi obtížně za cenu nákladů vyšších než v případě jejich kontinuálního řízení.
Rozšířený pohled na užití dat může poskytnout OLAP kostka znázorňující na úrovni faktů aktuální naměřené vlastnosti dat popsané v oddíle 1. Jako dimenze tato kostka používá jednotlivé atributy, formy užití a jednotlivé vlastnosti dat. Všímavý čtenář jistě namítne, že užití jednotlivých atributů nemá vliv na naměřenou úroveň vlastnosti. Toto tvrzení však nemusí platit vždy. V případě subjektivních vlastností, jak již bylo naznačeno výše, se může úroveň vlastnosti pro jednotlivá užití lišit. Přidáním dalšího faktu definitivně ukážeme, že konstrukce OLAP kostky v této rozšířené struktuře nebylo samoúčelné. Jako další fakt lze totiž uvažovat úroveň vlastnosti, která je u daného atributu pro dané užití potřebná / požadovaná. Lze potom snadno znázornit takové případy, kdy dochází buď k nedostatečnému nebo naopak zbytečnému udržování úrovně příslušné vlastnosti. Stanovení této požadované úrovně lze docílit buď na základě interview s uživateli dat (doporučuje v rámci interview např. [6]), anebo na základě simulačního modelu, který bude popsán v oddíle 4. Vzhledem k tomu, že napříč všemi užitími je ve finále nutné se rozhodnout o jednotné míře vlastností, v jaké budou v systémech udržovány, lze očekávat, že při doplnění kostky na základě simulačního modelu budou požadované míry napříč užitími též shodné.
Náklady na nekvalitní data
Nekvalitní data v důsledku svého užití přinášejí různé typy nákladů, které lze dále klasifikovat do různých kategorií. V prvé řadě jsou to přímé ekonomické náklady, představující dodatečné náklady na čištění dat, v případě duplicitních záznamů i náklady na správu redundantních zdrojů. Do ekonomických nákladů se přímo promítá také použití nekvalitních dat v procesech firmy (např. snížením efektivnosti přímé kampaně vlivem nedostatečné kvality kontaktních údajů nebo chybného zacílení nabídky vlivem nekvalitních dat o transakcích klienta). Z pohledu IT/ICT nekvalitní data zvyšují přímo náklady implementace nových aplikací. Na některé ekonomické náklady lze pohlížet rovněž jako na oportunitní náklady. Do skupiny přímých ekonomických nákladů patří též náklady na opětovné vykonání procesu, v rámci něhož došlo k chybě (např. opětovné zaslání opravené faktury, nabídky, …).
Další náklady mohou firmě vzniknout na základě legislativních důsledků nekvalitních dat. Je tomu tak zejména z toho důvodu, že kvalita některých typů dat je přímo vyžadována právními normami (např. účetní data). Snížená kvalita takových dat může vést k postihům ze strany příslušného regulačního orgánu. Legislativní důsledky mohou mít též příčinu v chybném zpřístupnění citlivých údajů nesprávné osobě. Příkladem normy vyžadující kvalitu reportovaných dat je Basel II.
Další nepřímé náklady mohou vzniknout vlivem použití nekvalitních dat pro analytické účely. Jak uvádí odborníci z praxe, příprava dat zabírá zpravidla až cca 80% času procesu získávání znalostí z databází. Jednou z příčin této časové náročnosti je i nízká kvalita vstupních dat. V této souvislosti platí okřídlené rčení „Garbage In – Garbage Out“ pregnantně vyjadřující fakt, že zatímco na základě kvalitních dat mohu (ale nemusím) vytvořit dobrý model, na základě špatných dat mohu vytvořit pouze špatný model. Nízká úroveň dat může mít za následek i situaci, že některé modely nebude možné vytvořit vůbec.
Dopady do taktického a strategického řízení jsou dalším typickým důsledkem nekvalitních dat. V duchu pyramidy znalostí chybná data poskytují pouze chybné informace, na základě nichž mohu získat pouze chybné znalosti (viz analytické důsledky). Rozhodování na základě nepřesných znalostí je velmi ošemetné (zvláště, pokud znalosti pokládám za korektní) a může vést k chybným vizím nebo až ke ztrátě konkurenceschopnosti firmy.
V neposlední řadě vedou nekvalitní data ke snížení výkonnosti firmy, potažmo IT, jehož jsou data jednou z dimenzí řízení. Jakými konkrétními mechanismy je pokles výkonnosti způsoben? Nutnost permanentních kontrol snižuje efektivnost vykonávání jednotlivých procesů. Náklady na nekvalitní data vstupují do metrik výkonnosti firmy na všech třech úrovních řízení (operativní, taktické, strategické). Pokud uvažujeme řízení dat jako jednu z dimenzí řízení informatiky, zhoršení úrovně vlastností dat jako metrik výkonnosti řízení dat zprostředkovaně ovlivňuje i metriky výkonnosti řízení ostatních dimenzí informatiky (např. ekonomickou dimenzi formou dodatečných nákladů na datovou kvalitu).
Na firmu s nekvalitními daty dopadá též reputační riziko. Taková firma oslovuje své klienty nabídkami, které nijak neadresují jejich reálné potřeby, ač zaštítěna slogany o důležitosti klienta vystavuje soustavně chybné faktury, není schopna základních servisních činností jako je v případě pojišťovny vydání správného daňového potvrzení u životního pojištění. Takové selhání musí nutně vést k negativnímu word-of-mouth efektu. Firma postupně ztrácí pověst seriozního partnera a ztrácí bonitní klienty, tedy to nejlepší, co má.
Nekvalitní data však mohou mít i katastrofické následky. Jak jinak lze mluvit o situaci, kdy 7. května 1999 bombardovala spojenecká vojska místo nepřátelských cílů v bývalé Jugoslávii čínskou ambasádu. Oficiální příčinou byly v tomto případě neaktuální mapy. Jak daleko v tu chvíli stál svět od dalšího válečného konfliktu s nedozírnými následky? Pro další příklady není třeba chodit daleko. M. Wheatley popisuje prodlevy v dodávkách zásob a doručování položek odlišných od požadovaných vlivem nízké datové kvality během války v Iráku. Co znamená takové selhání logistiky pro morálku mužstva? V r. 1998 došlo vlivem navigační chyby (odlišné měrné jednotky používané v rámci různých středisek řízení letu) ke zřícení sondy Mars Climate Orbiter. Paradoxní situace v době, kdy si málokterá země může dovolit vlastní vesmírný program. Lze si vůbec představit, že by se jednalo o let s lidskou posádkou? Ale držme se při zemi. Lépe snad nelze uvést další příklad tristního důsledku chybných dat. Je jím kauza Enron, „největší účetní skandál v historii“.
Uvedená struktura nákladů na nekvalitní data může být diskutabilní. Proto zde zmíním ještě další alternativní přístupy k jejich klasifikaci. Např. David Loshin v [6] člení náklady do následujících kategorií: Finanční dopad (přímé operační náklady, režijní náklady, dodatečné poplatky, změny v cash-flow, dopad do odpisů a úniku peněž z firmy např. v důsledku fraudů), dopad do spokojenosti spotřebitele a jeho očekávaného tržního chování, dopad do rizika a kompliance a konečně dopad do produktivity firmy. Jiný guru v oblasti kvality dat a informací, Larry English, rozlišuje v [3] tyto kategorie: (1) Náklady plynoucí přímo z nekvalitních informací, (2) náklady na assessment nebo kontrolu, (3) náklady spojené se zlepšováním procesů a předcházením defektům. Oba uvedení autoři se shodují v nutnosti namapovat defekty v datech na jejich příčiny. Postup mapování označují za Root-Cause analýzu.
Modelování kauzalit mezi příčinami, vlastnostmi a náklady
Zakomponováním nákladů do OLAP kostky jsme získali úplný podklad pro mapování kauzalit mezi úrovní vlastností daného atributu, jeho užitím a výslednými náklady (v členění podle výše uvedených skupin). Kauzality lze sledovat buď na úrovni jednotlivých atributů, anebo z pohledu celku. Náklady lze též chápat jako negativní přínosy a celou úlohu tak transformovat na úroveň sledování přínosů dat (ve smyslu celkové bilance firmy, v angl. literatuře označované jako bottom line) podmíněných vlastnostmi atributů a jejich užitím. Pokud abstrahujeme od možnosti měnit stávající a potenciální užití, jediným volitelným parametrem úlohy jsou úrovně vlastností dat. Nastavováním jejich různých hodnot můžeme získat jejich optimální úroveň, při níž bude firma dosahovat nejvyšších přínosů z dat (resp. nejnižších nákladů z nekvalitních dat). Vznikne tak jakýsi simulační model, jehož nastavení lze řešit jako klasickou optimalizační úlohu. Příklad grafického znázornění kauzalit zobrazuje obrázek č. 1.
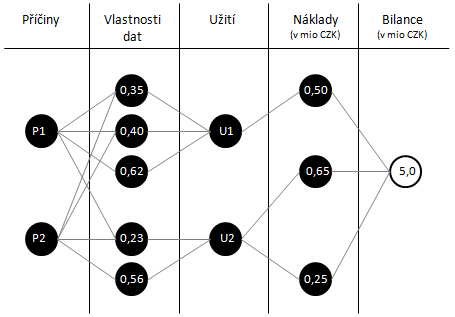
Obrázek 1 uvažuje navíc ještě zakomponování příčin pro jednotlivé vlastnosti dat tak, jak jej pomocí Root-Cause analýzy doporučuje např. [6]. V uzlových bodech mapy lze uvažovat buď konkrétní hodnoty, přičemž výsledná bilance představuje lineární kombinaci vlastností dat a jejich užití, anebo lze konkrétní hodnoty nahradit fuzzy množinami tak, jak uvádí např. [4]. Zjednodušení pomocí fuzzifikace je též ve shodě s přístupem publikovaným [6], který v rámci prioritizace uvažuje jednotlivým zjištěným defektům přiřazení stavů: kritický pro byznys, vážný, lze tolerovat, známý defekt. Sílu vazby mezi jednotlivými uzly sítě je možné graficky odlišit pomocí tloušťky hrany. Původní koncept pro aplikaci FCM publikovaný v [4] uvažoval naučení kauzální mapy z dat jako v případě neuronové sítě. Současně [4] podává řadu příkladů aplikace tohoto přístupu v rámci různých praktických úloh napříč různými předmětnými oblastmi. Naučení sítě jako prediktivního modelu bylo však ve všech těchto případech podmíněno existencí dostatečného množství pozorování. V našem případě tento předpoklad nejspíš splněn nebude. Praktická aplikace této metody by tedy v našem případě byla spíše než na modelu založena na konkrétních kalkulovaných případech a expertních pravidlech zjištěných praxí. Alternativně lze náklady / celkovou bilanci nahradit jiným ukazatelem výkonnosti firmy, např. počtem spokojených zákazníků.
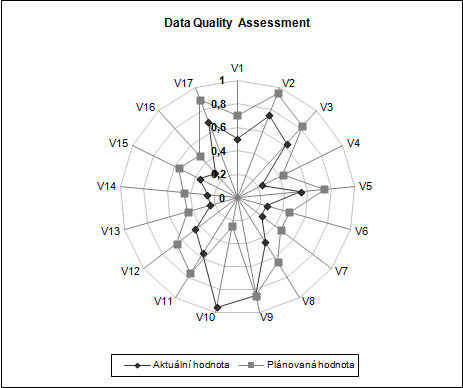
Jinou, zjednodušenou formu zobrazení kauzalit může představovat pavučinový graf zachycující na jednotlivých osách naměřenou / zjištěnou úroveň vlastností, optimálně přepočtenou na související náklady. Opět buď na úrovni jednotlivých atributů, či na globální úrovni přes všechny atributy. Výhodou této formy vizualizace je možnost přehledného zobrazení zamýšlené úrovně vlastností vedle té aktuální. Pro účely prezentace vrcholovému vedení zajisté velmi zajímavé.
Závěr
Pojem datová kvalita lze ztotožnit s úrovní požadovaných vlastností dat. V kombinaci se svým užitím, ať již stávajícím nebo potenciálním, se úroveň vlastností dat projevuje v nákladech a celkové bilanci firmy. Pro znázornění vazby vlastností, užití a nákladů lze použít např. kauzální mapy. Mapa může představovat simulační model, v rámci něhož lze kalibrovat jednotlivé vlastnosti dat tak, aby výsledný dopad do celkové bilance byl co nejpřijatelnější. Alternativně lze bilanci nahradit libovolnou metrikou výkonnosti firmy. Zjednodušeně lze vliv úrovně vlastností vizualizovat pomocí pavučinového grafu.
Námětem pro další výzkum je jednak praktická realizace simulačního modelu ve formě aplikačního SW, jednak vytvoření znalostní báze popisující jednotlivé kauzality typické pro užití v rámci jednotlivých vertikál.
Použitá literatura
- [1] BATINI, Carlo, SCANNAPIECO, Monica. Data Quality: Concepts, Methodologies and Techniques. Berlin: Springer-Verlag, 2006. xix, 262 s. ISBN-10 3-540-33172-7.
- [2] BERSON, Alex, DUBOV, Larry. Master Data Management and Customer Data Integration for a Global Enterprise. McGraw-Hill Companies, 2007. xxi, 393 s. ISBN-10 0-07-226349-0.
- [3] ENGLISH, Larry P. Improving Data Warehouse and Business Information Quality: Methods for Reducing Costs and Increasing Profits. Wiley & Sons, 1999. xxvi, 518 s. ISBN-10 0-471-25383-9.
- [4] GLYKAS, M. (Ed.). Fuzzy Cognitive Maps: Advances in Theory, Methodologies, Tools and Applications. In Studies in Fuzziness and Soft Computing, Volume 247. Berlin Heidelberg: Springer-Verlag 2010. s. 426. ISBN 978-3-642-03219-6.
- [5] LEE, Yang W., PIPINO, Leo L., FUNK, James D., WANG, Richard Y. Journey to Data Quality. The MIT Press, 2006. 240 s. ISBN-10 02-621-2287-1.
- [6] LOSHIN, D. The Practitioner’s Guide to Data Quality Improvement. Burlington: Morgan Kaufmann as inprint of Elsevier, 2011. ISBN 978-0-12-373717-5.
- [7] McGILVRAY, D. Executing Data Quality Projects: Ten Steps to Quality Data and Trusted Information. Morgan Kaufmann, 2008. xviii, 325 s. ISBN 978-0-12-374369-5.
- [8] PIPINO, L., LEE, Y. W., WANG, R.Y. Data quality assessment. Communications of the ACM 45(4) (2002). 211-218.
- [9] REDMAN, T. Data Quality: The Field Guide. Boston: Butterworth-Heinemann MA, 2001. xviii, 241. ISBN-10 1-55558-251-6.
- [10] ZELENÝ M.: Management Support Systems: Towards Integrated Knowledge Management. Human Systems Management, Vol. 7 no. 1 (1987) 59 – 70.
Poznámka: Tento článek byl původně publikován jako příspěvek na konferenci 4th INTERNATIONAL SCIENTIFIC CONFERENCE FOR Ph.D. STUDENTS AND YOUNG SCIENTISTS, KARVINA, NOVEMBER 4th 2011.