Master Data Management
[1.2.2015] D. PejčochÚvod
Při vyslovení pojmu Master Data Management jedni pomyslí na potenciálně předražený projekt s rizikem implementace vyšším než implementace samotného datového skladu, druzí podotknou, že vlastně každý subjekt ve skutečnosti ve větší či menší míře kmenová data řídí. Cílem tohoto článku je definovat, co jsou to kmenová data, stručně představit hlavní motivy k implementaci, základní typy a koncepty tvorby MDM řešení a nastínit hlavní úskalí při implementaci tohoto typu řešení.
Co jsou to kmenová data a jejich řízení
Kmenová data lze jednoduše označit jako data popisující aktiva (angl. Assets). Tato aktiva mohou být hmotná (osoby, jejich adresy, kontakty, hmotné produkty, součástky, komponenty) či nehmotná (např. finance). Naproti tomu transakční data představují události, které jsou s kmenovými daty spojeny (např. finanční transakce). S kmenovými daty je často spojován pojem referenční data. Za referenční data lze považovat taková, která jsou používána jako jakýsi etalon, jakýsi zdroj jediné pravdy, na který se ostatní data odkazují a používají jej pro validaci. Z tohoto pohledu lze nalézt určitou analogii s kmenovými daty, která jsou často rovněž používána jako zdroj jediné pravdy o entitách, které popisují. V praxi jsou však tyto pojmy používány odděleně. Jako referenční data jsou zpravidla označovány číselníky a externí registry, které jsou samy většinou používány jako jeden z mnoha zdrojů kmenových dat. Kromě referenčních dat slouží jako zdroje kmenových dat též subjektově orientované systémy (např. CRM) nebo datový sklad.
Příkladem kmenových dat vztahujících se ke klientům organizace mohou být:
- Základní charakteristiky klienta (jméno, příjmení, název firmy, datum narození, …);
- Primární identifikátory klienta (RČ, číslo sociálního pojištění, IČO, …);
- Kontaktní údaje (email, telefon, mobil, …);
- Adresní údaje (trvalé bydliště, korespondenční adresa, …);
- Segmenty, profily (behaviorální, demografický);
- Hodnota klienta (CLV, Customer Lifetime Value) nebo segmenty z hodnoty odvozené, případně jednotlivé složky hodnoty jako je současná hodnota, budoucí hodnota, revenue, související kategorie nákladů;
- Příznaky uživatelských referencí (zákazykontaktování, preferované komunikační kanály, uživatelské preference na online portálu, …);
- Příznaky procesů segmentovaných podle hodnoty klienta;
- Hierarchie a role;
- Scorecard s hlavními metrikami výkonnosti a spokojenosti.
Pro řízení kmenových dat, Master Data Management, existuje celá řada různých definic. Tyto definice často zmiňují, že se jedná o proces řízený workflow, zajišťující konzistentnost, správnost a řízení přístupu ke klíčovým informacím organizace. Stejně tak, jako na ostatní oblasti řízení kvality dat / informací, i na Master Data Management lze uplatnit principy postupného zlepšování zakotvené v principech Gemba Kaizen.
Dyché a Levy publikovali svého času tzv. Hierarchii řízení dat, v rámci níž je MDM umísteno mezi Globální datovou kvalitu (sdílené principy napříč firmou) a Data Governance (řízení dat jako klíčového aktiva organizace). Toto pořadí koresponduje s úrovní řízení, kam příslušná činnost patří. Zatímco Data Governance patří do strategické úrovně, MDM patří do úrovně taktické. Je však nutné vzít v potaz, že MDM nelze úspěšně implementovat bez toho, aniž by dříve došlo k zakotvení základních principů, politik, pravidel a definice odpovědnosti za data, tedy typických rysů Data Governance.
Co lze tedy označit za hlavní cíle MDM? V prvé řadě je to zabezpečení jednotného pohledu na vybraná kmenová data. Master data představují „jedinou verzi pravdy“ o kmenových datech. Za sekundární cíle lze označit rozpoznání individuí a jejich vztahů. Báze kmenových dat by měla odpovědět na otázku kdo je náš klient, které dílčí účty lze považovat za jednoho klienta, s kterými dalšími klienty tvoří rodinu, rozhodování jakých dalších subjektů je schopen ovlivňovat, buď na základě své formální role, anebo pomocí podané ústní reference (tzv. word-of-mouth vztahy). Mezi další cíle MDM patří zajištění bezpečnosti a visibility Master Dat. Pokud MDM řešení představuje jedinou formu publikace kmenových dat, je snadné jej použít jako nástroj pro řízení přístupu k těmto datům. V neposlední řadě slouží MDM řešení jako nástroj zajištění souladu (compliance) s některými regulacemi vyžadujícími zajištění jednotného pohledu na klienta (např. Basel II). Právě nutnost zajištění tohoto souladu bývá jedním z nejčastějších driverů pro implementaci MDM řešení.
Formy implementace
Z pohledu formy realizace MDM řešení lze hovořit o čtyřech různých variantách:
- Operativní MDM: realizováno tzv. proti proudu obecných datových toků. Tato forma je reprezentována jedním nebo více MDM zabudovanými do aplikací za účelem jejich integrace. Definice entit je v čase zpravidla neměnná. Typickým příkladem je produktový katalog.
- Analytické MDM: realizováno tzv. po proudu datových toků. Typicky představuje součást datového skladu. Definice entit je značně proměnlivá. Příkladem může být MDM řešení orientované na data klientů / zákazníků.
- Enterprise MDM: představuje autonomní infrastrukturu založenou na integraci dat z mnoha systémů. Uvažuje obousměrné datové toky, vytvoření unifikované datové báze směrem po proudu datových toků a následně propagaci informací z MDM do jednotlivých satelitních aplikací proti proudu datových toků.
- Collaborative MDM: představuje systém založený na workflow umožňující činnosti jako eskalace kandidátů na sloučení nebo proces schvalování zavedení nového produktu do produktového katalogu.
Podle míry synchronizace metadat s ostatními aplikacemi lze uvažovat několik implementačních scénářů:
- Konsolidace: je založena na vytváření tzv. zlatého záznamu na základě dat pocházejících z různých core / satelitních systémů. Změny jsou propagovány do po směru datových toků např. do datového skladu, kde probíhá jejich konsolidace a vytváření unifikované báze;
- Forma registru: poskytuje minimum informací ostatním systémům formou reference na jiné aplikace (např. referenční ID unifikovaného produktu s odkazem na klíč produktového katalogu satelitní aplikace);
- Forma koexistence: MDM řešení je synchronizováno se zdrojovými systémy a předává do nich „zlatý záznam“. MDM tak není jediným místem, kde jsou data aktualizována;
- Transakční Hub: Vešekerá komunikace prochází skrz MDM Hub. Do ostatních systémů jsou propagovány jen jedinečné identifikátory a všechny ostatní atributy poskytuje na základě volaní příslušné služby MDM Hub.
Z pohledu implementačních scénářů uvedených výše, tím zdaleka nejčastějším a nejjednodušším je konsolidace, nejméně častým a nevíce obtížným je realizace transakčního hubu. V podstatě lze říci, že dnes již téměř každá organizace má v menší či větší míře vytvořenou offline konsolidovanou bázi kmenových dat a tedy implementovaný alespoň minimalistický Master Data Management.
Mezi nejčastější řešení MDM z pohledu zaměření lze bez nadsázky označit ta orientovaná na klientská data (Customer Data Integration, CDI) nebo data produktů (Product Information Mangement, PIM). Méně častými jsou řešení orientovaná na zajištění jednotného pohledu na kreditní skóring klienta (Financial Performance Management) či Citizenship Management. S rostoucí hrozbou terorismu lze však očekávat, že právě řešení typu Citizenship Management budou nabývat čím dál tím většího významu, hraničícím až s konceptem Velkého Bratra.
Architektura MDM řešení
Základní komponenty architektury MDM řešení tvoří unifikovaná a deduplikovaná báze, představující tzv. System-of-Record, tedy jedinou verzi pravdy pohledu na vybraná kmenová data, a tzv. MDM Hub, reprezentující systém služeb fungující jako jediný přístupový bod k datům uloženým v System-of-Record. Služby tvořící MDM Hub jsou zpravidla podmnožinou komplexní architektury ESB (Enterprise Service Bus) dané organizace. Při jejich implementaci je vhodné dodržovat některé osvědčené principy tvorby ESB, jako jsou pravidla SOA (Servisně orientované architektury) a použití obecného kanonického datového modelu, který je jednotný pro celé ESB a na nějž jsou mapovány elementy zpráv zasílaných jako prostředek komunikace jednotlivými aplikačními službami. Mezi základní principy SOA lze zařadit:
- Rozdělení logiky nezbytné pro řešení nějakého problému na kolekci menších vzájemně souvisejících částí;
- Zapouzdření logiky;
- Vzájemná komunikace na základě znalosti popisu služby;
- Použití zpráv jako nezávislé jednotky komunikace;
- Abstrakce: služby skrývají logiku před okolním světem;
- Znovupoužitelnost služby v rámci více rozhraní;
- Kompozice: služby lze uspořádat, aby vytvořili spojené služby (zpravidla se potom hovoří o tzv. Orchestraci nebo choreografii jednotlivých služeb);
- Služby založené na otevřených standardech: SOAP (Simple Object Access Protocol), WSDL (Web Service Description Language), XML, XSD (XML schéma);
- Zjistitelnost: existence registru umožňujího mechanismus pro zjištění služeb;
- Federace: možnost nastolení jednotnosti v dříve nesdružených částech podniku;
- Rozšiřitelnost o nové služby bez nutnosti rozbíjení stávajících rozhraní.
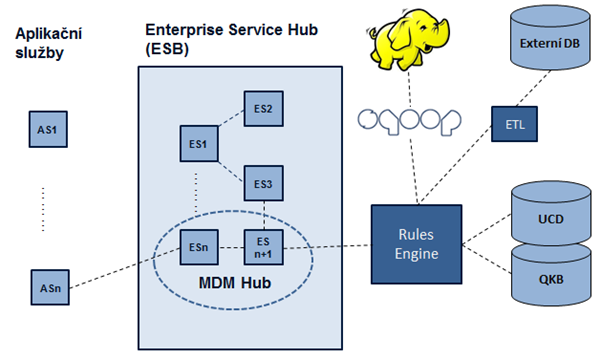
Příklad architektury MDM řešení založeného na kombinaci unifikované báze a MDM Hubu ukazuje Obrázek č. 1. Aplikační služba ASn na něm volá enerprise službu ESn (např. vložení nového klienta), která je součástí MDM Hub. Ta k vykonání požadovanné činnosti potřebuje součinnost služby Esn+1 (např. dotaz na existujícího klienta), která následně volá službu ES3 orchestrující služby ES1 a ES2. Tyto služby jsou však používány i jinými procesy, než v rámci MDM. Na uvedeném příkladu služba ESn+1 komunikuje s unifikovanou bází prostřednictvím Rules Engine, který zajišťuje standardizaci a validaci dat, případně aplikaci KO kriterií pro sloučení záznamů. Na schématu jsou rovněž uvažovány dávkové přenosy z externích DB a ekosystému Hadoop.
Datová integrace
Pro CDI implementace je typické řešení porovnávání nově vstupujících klientských záznamů se stávající unifikovanou a deduplikovanou bází. Otázka deduplikace je zpravidla realizována ve dvou krocích:
- úvodní deduplikace pomocí identifikace shluků podobných záznamů, z nichž je poté vybrán / sestaven tzv přeživší záznam (surviving record);
- následné porovnávání nově příchozích záznamů s již deduplikovanou klientskou bází.
O jednotlivých technikách použitelných pro deduplikaci vyčerpávajícím způsobem hovoří jiný článek publikovaný na tomto portálu. Existence značného množství těchto technik budí dojem, že automatická deduplikace je naprosto běžným jevem. Opak je však pravdou. V praxi se můžeme setkat s celou řadou případů, kdy není možné o sloučení v danou chvíli rozhodnout a je nutné manuální posouzení tzv. kandidátů na sloučení. Příčinou je jednak problematická výkonnost některých algoritmů pro deduplikaci, která často znemožňuje jejich použití v reálněm čase, tak i skutečnost, že 100% spolehlivost těchto metod je pouhý mýtus. V případě výkonnosti algoritmů se samozřejmě nabízí polemika, v jaké míře lze pro online deduplikaci využít v dnešní době populárního zpracování v rámci clusterů. Z pohledu spolehlivosti algoritmů bývá v praxi menším zlem záznamy nesloučit než sloučit. Např. skutečnost, že jediný klient má v systému uvedené dva účty a na základě této skutečnosti je mu nabídnut dvakrát ten samý produkt bude mít menší dopad, než pokud by klient viděl v online bankovnictví transakce jiného klienta.
Kromě problémů, plynoucích z vlastností použitých metod samotných, existuje celá řada byznys důvodů, proč konkrétní záznamy klientů nesloučit (např. se jedná o dva odštěpné závody pod jedním IČO). Tyto důvody by měly být definovány formou byznys pravidel uložitelných v QKB (znalostní bázi orientované na podporu řízení kvality dat) a aplikovatelných pomocí Rules Engine zmíněným výše.
Určité úskalí přestavuje rovněž řešení úvodní deduplikace a hledání přeživšího záznamu. Je to ten nejnovější? Nejúplnější? Nejvalidnější? Ten s nejvíce navázanými transakcemi? V praxi je vhodné definovat takový přístup, kdy je kalkulováno vážené skóre na základě všech uvedených vlastností. Nejlepším kandidátem je potom záznam s nejvyšším skóre. Nastavení jednotlivých vah musí zohledňovat procesy konkrétní firmy.
Závěr
Již z pohledu na popis architektury řešení je zřejmé, že investice do jeho implementace může představovat značné riziko, zejména pokud se jedná o nejčastější realizovanou formu MDM, CDI (Customer Data Integration). Jestliže v případě klasických DWH řešení je zmiňován podíl neúspěšných implementací až okolo 80 %, v případě MDM lze předpokládat, že toto procento bude ještě daleko vyšší. Jedná se totiž ve své podstatě o vytvoření řešení části datového skladu (pokrývajícího vybraná kmenová data), workflow logiky řešící nově příchozí záznamy kmenových dat a integraci s core a satelitními systémy, která si může vyžádat zásah do vnitřní logiky všech těchto aplikací a současných interfaců. Z těchto důvodů je na Master Data Management často pohlíženo velmi kriticky jako na něco co vpodstatě není potřeba a generuje pouze enormní náklady při minimu přínosů a co navíc může způsobit dlouhodobé nežádoucí zaháčkování dodavatelů v organizaci.
Otázkou je, zda je vždy nutné uvažovat maximalistickou variantu implementace, zda nezačít nejprve s offline unifikovanou bází a po zajištění quick wins v oblastech jako je CRM nebo risk management pokračovat pozvolna s dopracováváním integrace na okolní systémy, pokud bude existovat skutečný byznys důvod. V každém případě je nutné při implementaci postupovat maximálně obezřetně. Na jednu stranu je sice nutné činit rázná rozhodnutí, na druhou stranu je nutné pamatovat na to, že některé změny mohou být nevratné nebo jen obtížně napravitelné, např. za cenu značných nákladů a ztráty reputace. V oblasti MDM platí více než kde jinde, že datová kvalita (tedy i deduplikovaná data) je vždy dodatečná informace*.
Doporučené zdroje
- PEJČOCH, D. Využití Fuzzy Match algoritmu pro čištění dat. [online]. 2008-01-17. Dostupné na: http://www.dataquality.cz/vyzkum/cl_fuzzy_match_porovnavani_retezcu.pdf.
- PEJČOCH, D. Benchmark přístupů k Fuzzy Match / Merge. Sborník prací účastníků vědeckého semináře doktorského studia. Fakulta informatiky a statistiky VŠE. Praha 2009. ISBN 978-80-245-1524-3.
- CHAPPELL, D. A. Enterprise Service Bus. Sebastopol: O’Reilly, 2004. ISBN: 0-596-00675-6.
- ERL, T. Service-Oriented Architecture, A Field Guide to Integrating XML and Web Services. Prentice Hall, 2004.
- BERSON, Alex; DUBOV, Larry. Master Data Management and Customer Data Integration for a Global Enterprise. McGraw-Hill Companies, 2007. xxi, 393 s. ISBN-10 0-07-226349-0.
- LOSHIN, D. Master Data Management. Elsevier, 2008. ISBN: 9780080921211.
- DYCHÉ, Jill, LEVY, Evan. Customer data integration: Reaching a Single Version of the Truth. SAS Institute Inc., Wiley & Sons, 2006, xxiv, 294 s. ISBN-10 0-471-91697-8.
- DREIBELBIS et kol. Enterprise Master Data Management: An SOA Approach to Managing Core Information. IBM Press, 2008. ISBN: 0132366258.
* tuto větu jsem před cca deseti lety poprvé slyšel od Vladimíra Kyjonky ze SASu, a proto ji na svých přednáškách zpravidla uvádím pod označením “první Kyjonkova věta”.