Imputace pomocí nástroje Rapid Miner
[27.10.2014] D. PejčochÚvod
Problematiku chybějících pozorování lze bez nadsázky označit za jednu z nejdůležitějších oblastí řízení kvality dat. Toto téma bylo zdokumentováno dávno před tím, než se začal skloňovat samotný pojem kvality dat. I v případě, že firma nemá implementovány žádné validační kontroly, musí se v rámci realizovaných analýz potýkat s faktem, že některá pozorování chybí. V okamžiku, kdy se analytik rozhodne aplikovat jakoukoliv sofistikovanější metodu analýzy dat, musí se s problémem chybějících pozorování nějakým způsobem vypořádat. Cílem tohoto článku je popsat řešení problematiky chybějících pozorování pomocí nástroje Rapid Miner. Článek popisuje postup vytvoření prostředí pro porovnání různých alternativních metod pro imputaci.
Imputace jako metoda řešení chybějících pozorování
(Dasu & Johnson, 2003) uvádí dva různé typy neúplných dat: chybějící záznamy ve smyslu nevyplněných hodnot vybraných pozorování daného atributu a problematiku nekompletních záznamů související s cenzorováním dat. Druhý uvedený případ úzce souvisí s analýzou přežití. Jedná se o situaci, kdy je modelována doba do výskytu události (např. v životním pojištění úmrtí pojištěné osoby nebo v neživotním pojištění realizované storno smlouvy klientem). Může se stát, že k danému jevu u konkrétního subjektu během pozorování nedojde, přestože víme, že u něj jev v budoucnu zákonitě nastat musí. V tomto případě hovoříme o cenzorování zprava. Podobná situace nastává, pokud nemáme o subjektu k dispozici naměřená data z období před určitým datem (počátkem výzkumu, vznikem firmy, příchodem klienta od jiné firmy,…) a k sledované události došlo před tímto datem (např. k pojistnému podvodu). Za takové situace hovoříme o cenzorování zleva. Zatímco v případě chybějících hodnot nemáme k dispozici pozorování, ačkoliv bychom jej mít měli, v případě cenzorovaných dat nemáme pozorování k dispozici, protože leží mimo časový úsek, během něhož probíhal sběr dat o daném subjektu. Tento článek se zaměřuje na problematiku nevyplněných hodnot.
Klasifikace alternativních přístupů k řešení problematiky chybějících pozorování byla publikována v (Pejčoch, 2014). Navržená klasifikace rozlišuje mezi triviálními metodami, kdy jsou chybějící pozorování (1) ignorována, překódována či vypuštěna, (2) metodami založenými na doplnění (imputaci) chybějících hodnot z referenčního zdroje, (3) metodami založenými na imputaci bez vytvoření modelu a (4) metodami imputace na základě vytvoření modelu. Volba konkrétní metody je závislá na tzv. mechanismu výskytu chybějících pozorování. Tento článek se soustředí na mechanismy MAR (Missing at Random), kdy lze chybějící pozorování doplnit na základě hodnot ostatních atributů.
Popis vytvoření rámce pro imputaci v Rapid Miner
Rapid Miner představuje jednen z nejoblíbenějších nástrojů pro získávání znalostí z databází. K obecné oblibě přispěl kromě značně košaté funkcionality i fakt, že donedávna byl k dispozici jako zcela volně stažitelný (nyní volně dostupný pouze v rámci tzv. Starter Edition) a v současné době pro komerční účely dostupný za cenu nesrovnatelně nižší než jiné srovnatelné nástroje. Mezi nesporné výhody použití Rapid Miner patří též reprezentace data flow formou XML konfiguračního souboru. Vzhledem ke známé chybějící podpoře PMML (Predictive Model Markup Language) pro krok přípravy dat, bohužel odlišného od tohoto standardu. Tato reprezentace umožňuje snadný přenos již vytvořeného data flow do jiné instance Rapid Miner, přímé spuštění data flow z příkazové řádky a také vygenerování data flow některým externím nástrojem.
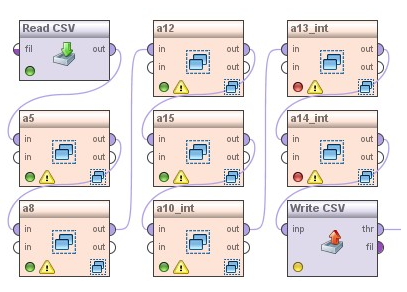
Pro účely imputace založené na modelu jsem použil data flow znázorněné na obrázcích 1, 2 a 3. Obrázek 1 ukazuje nevyšší úroveň granularity data flow. V rámci uzlového bodu Read CSV dochází k načtení zdrojových dat s vyskytujícími se chybějícími pozorováními. Uzlové body a5, a8, a12, a15, a10_int, a13_int a a14_int odpovídají dílčím procesům imputace chybějících hodnot vyskytujících se v rámci proměnné se shodným názvem jako je název procesu. Výstupy jednotlivých dílčích procesů představují vstup navazujícího procesu. Na závěr celého data flow je výsledný data set exportován pomocí uzlového bodu Write CSV.
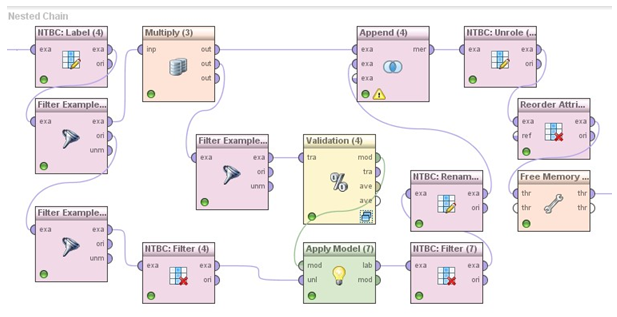
Obrázek 2 znázorňuje vyšší úroveň detailu odpovídající dílčímu procesu imputace, shodnému pro všechny imputované proměnné. V rámci uzlového bodu NTBC: Label je nejprve imputované proměnné přiřazena role Label (odpovídá roli Target, známé z jiných nástrojů pro získávání znalostí z databází). Proměnným, které nejsou podstatné pro imputaci, jsou přiřazeny role Ignore1 – Ignoren (kde n je počet ignorovaných proměnných). Takto označené proměnné budou vyjmuty z dalšího zpracování, dokud jim nebude zpět přiřazena některá z konvenčních rolí, např. obecná Regular. Poté jsou pozorování rozdělena na dvě skupiny podle výskytu chybějících hodnot v rámci proměnné v roli Label.
Pozorování s úplnými hodnotami imputované proměnné jsou následně ještě filtrována podle výskytu chybějících hodnot v rámci proměnných použitých v roli prediktoru. Vlastní prediktivní model je potom vytvořen na této úplné sadě hodnot a aplikován na pozorování s chybějícími hodnotami, z nichž byla nejprve odstraněna imputovaná proměnná. Ta je v rámci aplikace modelu nahrazena proměnnou prediction(název_imputované_proměnné). Role uzlového bodu NTBC: Rename poté spočívá v přejmenování této umělé proměnné na původní název imputované proměnné. V rámci uzlového bodu Append jsou potom sady pozorování s imputovanými hodnotami a pozorování s úplnými hodnotami imputované proměnné sjednoceny do jednoho výstupu. Uzlový bod NTBC: Unrole následně nastaví role všech proměnných s výjimkou primárního klíče na hodnotu Regular. Nakonec je provedeno setřídění proměnných podle předem definovaného pořadí, uvolnění paměti a předání datového souboru do navazujícího kroku.
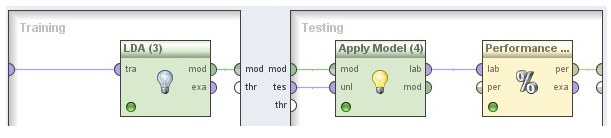
Obrázek 3 pouze ukazuje detail uzlového bodu pro křížovou validaci, která je použita při vytváření vlastního prediktivního modelu. Konkrétní metodu predikce reprezentuje uzlový bod LDA (Linear Discriminant Analysis). Pro aplikaci jiné metody stačí pouze v XML reprezentujícím příslušné data flow nahradit část odpovídající této metodě. Samozřejmě je nutné též upravit sadu použitých proměnných dat, aby korespondovala s předpoklady konkrétní metody.
Různé varianty XML představující konkrétní metody jsou k dispozici pod odkazem: http://www.dataquality.cz/kbase/index.php?title=RapidMiner:_Nodes_XML. Příklad pro výše zmiňovanou lineární diskriminační analýzu ukazuje Obrázek č. 4.
<process expanded="true"> <operator activated="true" class="linear_discriminant_analysis" compatibility="5.3.013" expanded="true" height="76" name="LDA" width="90" x="112" y="30"/> <connect from_port="training" to_op="LDA" to_port="training set"/> <connect from_op="LDA" from_port="model" to_port="model"/> <portSpacing port="source_training" spacing="0"/> <portSpacing port="sink_model" spacing="0"/> <portSpacing port="sink_through 1" spacing="0"/> </process>
Vytvořená data flow je možná spouštět přímo z GUI nástroje RapidMiner jednoduše tak, že připravené XML je načteno pomocí volby Import Process, případně vloženo přímo do záložky XML nově vytvořeného procesu. Tento způsob realizace však může činit určité problémy při značném množství imputovaných proměnných, resp. počtu použitých prediktorů. Validace takových data flow přímo z GUI může v prostředí s malou RAM vést k zatuhnutí celé aplikace. Proto je vhodnější pro spouštění data flow použít příkazové řádky, v prostředí OS Windows např. nainstalovaný GIT bash. Příklad syntaxe spuštění konkrétního data flow uloženého jako soubor s příponou rmp (Rapid Miner Process) ukazuje Obrázek č. 5.
r:\ROOT\install\kdd\RapidMiner\rapidminer\scripts\rapidminer -f r:\ROOT\wamp\www\dataqualitycz\vyzkum\Imputace\RMProjects\ds6_M16_30.rmp
V případě velkého počtu použitých data flow je jejich postupné manuální spouštění velmi nepohodlné. S využitím UNIX shell lze tuto činnost částečně automatizovat např. pomocí níže uvedeného skriptu. Ten předpokládá aplikaci konkrétní metody na celkem 12 různých datových souborů s mírou vygenerovaných chybějících pozorování v rozmezí 5 – 50 % s krokem rovným 5 %.
#!/bin/sh
for a in {1..12}
do
for i in 5 10 15 20 25 30 35 40 45 50
do
/home/dpejcoch/install/RapidMiner/rapidminer/scripts/rapidminer -f
/home/dpejcoch/RMProjects\ds“$a“_M16_“$i“.rmp
done
done
Závěr
Doplňování chybějících pozorování na základě explicitního modelu představuje jednu z možných metod imputace. V rámci mnou realizovaného experimentu bylo použito celkem 30 různých metod a 12 různých datových souborů. Generování jednotlivých data flow bylo realizováno pomocí skriptu napsaného v jazyku PHP s využitím metabáze implementované v MySQL, která definovala, které proměnné jsou pro konkrétní metodu přípustné a v jaké roli se mohou při imputaci vyskytovat. Podkladové materiály k realizovanému experimentu jsou dostupné pod níže uvedenými odkazy:
- Použité zdrojové kódy na GITHub: https://github.com/dpejcoch/DataImputation
- Popis použitých dat: http://www.dataquality.cz/index.php?ID=4&SUBID=2
- Schéma metodiky experimentu: https://github.com/dpejcoch/DataImputation/blob/master/DataImputationExperimentProcess.png
{kind=link}
Reference
- DASU, T., JOHNSON, T. Exploratory Data Mining and Data Cleansing. New Jersey: Wiley & sons, 2003.
- PEJČOCH, D. Benchmark metod pro doplňování chybějících pozorování. dataqualitycz [online]. 2014-10-18. [cit. 2014-10-18]. Dostupné pod: http://www.dataquality.cz/index.php?ID=4&SUBID=2