Big Data Quality - 1. díl
[29.6.2013] D. PejčochÚvod
V současné době je velmi moderní v různých souvislostech skloňovat pojem Big Data. Ve většině případů se pod tímto pojmem rozumí taková data, jež není možné efektivně zpracovat v požadovaném čase standardními prostředky relačních databází. Zpracování a analýza velkých dat je založena na kombinaci principů Cluster Computingu a NoSQL databázích. Tedy technologických prvcích, které nepředstavují ve světě informatiky žádnou novinku. Historické kořeny použití výpočetní síly clusterů sahají do 60. let minulého století. První komerční cluster spatřil světlo světa ve stejném roce, kdy jsem se narodil já (1977). O NoSQL databázích slýcháme dobrá dvě desetiletí.
Typickým rysem „Big Data“ je jejich stále se zvyšující objem, vysoká frekvence změn v čase při současném požadavku na jejich dostupnost téměř v reálném čase. Tyto tři uvedené vlastnosti korespondují s definicí pojmu publikovanou společností Gartner (3V: Volume, Velocity, Variety). V historických počátcích byly jako velká data zpracovávány rozsáhlé nestrukrurované soubory. Postupně však narůstala potřeba velká data před jejich zpracováním integrovat s dalšími zdroji. Z pohledu řízení kvality velkých dat je proto klíčové řízení kvality i těchto dílčích zdrojů. Samotný pojem Big Data Quality se začal vyskytovat jen krátce poté, co se začalo hovořit o velkých datech. Jestliže první z nich je některými autory považován za pouhý buzzword, Big Data Quality k tomuto závěru svádí tím spíš. V čem je tedy jiné řízení datové kvality v případě Big Data od řízení ostatních dat? Na tuto otázku bych rád odpověděl v tomto článku. Pokusím se přitom reflektovat všechny možné souvislosti velkých dat a jejich kvality.
Svět NoSQL databází
Jak již bylo naznačeno, pojem Big Data je nejčastěji chápán ve spojení s řešením typu Hadoop. Hadoop je jedním z možných rámců pro distribuované zpracování nestrukturovaných dat a jejich uložení v distribuovaném souborovém systému. Hadoop typicky používá fyzické úložiště, které patří do světa tzv. NoSQL (Not Only SQL) databází. V případě Hadoop se jedná o tzv. HBase, klon původní Big Table od společnosti Google používané při indexaci webového obsahu. HBase představuje zástupce tzv. sloupcově orientovaných databází. Kromě této skupiny do světa NoSQL databází lze řadit ještě dokumentové, grafové a „Key-Value“ databáze. Označení „NoSQL“ neznamená, že by obecně nebylo možné použít pro vytváření dotazů nad těmito zdroji jazyka SQL. Spíše akcentuje odklon od klasického modelu relační databáze. Nicméně pravdou je, že pro dotazování nad některými vybranými členy této poměrně rozsáhlé rodiny skutečně jazyka SQL použít nelze (např. pro RDF schéma je místo SQL používán jazyk SPARQL).
Architektura Hadoop je typicky založena na tzv. HDFS (Hadoop Distributed File System), škálovatelném, chybám odolném (fault tolerant) distribuovaném systému založeném na asynchronní replikaci. Základními stavebními prvky jsou zpravidla jeden master uzlový bod a sada jednotlivých pracovních nodů. Master node obsahuje funkcionalitu časovače, řídícího prvku jednotlivých úloh (tzv. job tracker) a správce metadat (tzv. name node). Realizuje rozdělení vstupních dat na 64 MB nebo 128 MB bloky, které poté distribuuje na jednotlivé pracovní nody. Každý blok dat je přitom standardně replikován třikrát. Pracovní nody spouští jednotlivé Map-Reduce úlohy umožňující v první fázi oindexování všech zpracovávaných dokumentů a jednotlivých čísel řádků tak, aby bylo v druhé fázi možné na úrovni master nodu deduplikovat a složit výsledky dílčích pracovních nodů do jednoho, poskytnutého uživateli. Krom toho pracovní nody obsahují vlastní úložiště dat (tzv. data node).
Problémy datové kvality spojené s Hadoop
Potenciální problémy Hadoop z pohledu datové kvality lze rozčlenit do několika rovin. První z nich je architektonické hledisko. Řada expertů z oblasti relačních databází (např. David de Witt a Michael Stonebraker) kritizují logiku Map-Reduce jako krok zpět v databázovém přístupu postrádající celou řadu vlastností osvědčených z klasických RDBMS a navíc nekompatibilní s DBMS nástroji. Pravdou je, že Map-Reduce úlohy jsou zpravidla psány „primitivně“ ručně v nějakém programovacím jazyce, typicky Java, C++, Python. Veškerá logika zabezpečující datovou kvalitu je tak natvrdo zanesena do zdrojového „spagetti“ kódu programátorem a je tak jen velmi nesnadno udržovatelná.
Samotná implementace Hadoop představuje tak trochu onu pověstnou vyšší dívčí. Toto řešení spoléhá na svou odolnost proti selhání jednotlivých komponent zajištěnou jak redundantními master nody, tak vícenásobnou replikací dat na jednotlivé pracovní nody. To je ovšem samozřejmě funkcionalita, jíž je nutné podrobit před nasazením pečlivému testování simulujícímu výpadky jednotlivých nodů.
Apache Hive, řešení pro datové sklady na platformě Hadoop, umožňuje velmi nesnadnou implementaci byznys logiky a její údržby formou uživatelsky definovaných funkcí. Řešit otázku kvality dat bude tudíž nejspíš vhodnější na straně zdrojových systémů, jejichž data Hadoop konzumuje. Na druhou stranu, Kolb a kol. publikoval studii v rámci níž popisuje aplikaci Dedoop provádějící deduplikaci záznamů v rámci Hadoop řešení. Postup deduplikačního algoritmu využívá standardních komponent pro blocking, použití měr podobnosti a automatické vytváření porovnávacích klasifikátorů s využitím metod strojového učení. Definici workflow Dedoop automaticky transformuje do Map-Reduce workflow.
Novinku ve světě Hadoop představuje HCatalog, nástroj pro správu metadat umožňující dalším aplikacím snadnější zápis a čtení dat v clusteru. HCatalog poskytuje např. interface pro nástroj Pig, analytickou platformu pro analýzu velkých dat obsahující vlastní jazyk vysoké úrovně. Nicméně např. Josh Rogers ve svém článku „Is ETL Dead in the Age of Hadoop?“ označuje tento nástroj za dosud „nezralý“.
Problémy kvality komplexních dat
Mnoho autorů, např. Steve Sarsfield, rozlišuje Big Data (myšleno Hadoop), Enterprise Data jako data střední velikosti (myšleno relační databáze) a diskrétní data (jednotlivé soubory) jako data malé velikosti. Otázku kvality velkých dat však nelze redukovat pouze na NoSQL databáze, potažmo jednu jejich konkrétní formu použití (Hadoop). Nelze ignorovat fakt, že velká data jsou často pro účely anlaýzy integrována s dalšími, středně velkými (např. údaji z datového skladu) a malými daty (např. číselníky). V širším pojetí tak lze problematiku Big Data Quality chápat jako otázku řízení kvality všech potenciálně užitečných dat, která firma používá. Tato data mohou být jak strukturovaná, tak semistrukturovaná, anebo dokonce nestrukturovaná. Univerzum zdrojů velkých dat tak lze z technologického pohledu rozčlenit na RDBMS, nerelační databáze, databáze založené na KVP (Key-Value Pair) principu (např. Riak), dokumentové databáze (např. MongoDB nebo CouchDB), sloupcově orientované databáze (např. HBase), grafové databáze (např. Neo4J), prostorové databáze, „In Memory“ databáze, různé klony XML (SOAP, RDF, OWL, JSON, ...), textové soubory s různou mírou strukturalizace a konečně multimediální soubory (obrázky, audio, video, stream). Z pohledu původu dat lze uvažovat jak interní, tak externí data. Z pohledu dostupnosti jsou tato data k dispozici v dávkovém režimu, online na základě dotazu, tak i v reálném čase. Rozmanitost tohoto Univerza znázorňuje Obrázek č. 1.
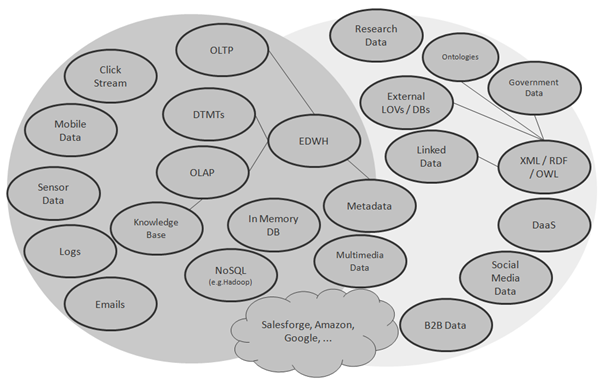
Otázky spojené s kvalitou velkých dat
V souvislosti s kvalitou velkých dat lze řešit následující okruhy problémů, vyplývajících z konkrétní formy využití velkých dat a jejich začlenění do IT architektury firmy:
- Proaktivní řešení kvality zdrojů velkých dat na bázi principů globálního Data / Information Governance;
- Retrospektivní řešení kvality velkých dat přímo v rámci technologických prvků tvořících platformu pro velká data;
- Využití velkých dat jako zdroje pro obohacení stávajících dat;
- Využití velkých dat jako zdroje pro validaci stávajících dat;
- Využití výpočetní síly platformy pro velká data pro řízení kvality stávajících dat.
Jednoltlivé okruhy postupně popíšu v rámci následujících kapitol.
Problémy Data Governance
Právě až neuvěřitelné spektrum všech představitelných technologií stojících za jednotlivými zdroji dat je jedním z typických problémů řízení kvality dat a Data Governance takto chápaného univerza. Lze si jen těžko představit doménově orientovaného datového stewarda (dosud se úspěšně vypořádávajícího s jazykem SQL), který by postihl všechny technologické aspekty takto různorodého světa. Nabízí se zde samozřejmě alternativa v podobě oddělení technologického a obsahového hlediska (oddělení technických a doménových stewardů). Jak ale tato berlička obstojí za situace stále se zvětšujícího množství dat externího charakteru? Bude vždy možné se spolehnout na to, že externí data budou kvalitně spravována externími stewardy a opatřena kvalitními metadaty tak, aby na straně jejich konzumenta musel být pouze doménově orientovaný steward zcela odstíněný od technologie na straně dodavatele? Anebo bude muset firma najímat univerzální experty na všechny používané technologie?
V poslední době, snad ještě více než pojem Big Data, skloňuje se pojem Data Science a od něj odvozené označení role Data Scientist. V souvislosti s Data Science se hovoří o souboru znalostí z oborů jako je matematika, statistika, datové inženýrství, získávání znalostí z databází / textů / webu / multimédií, vizualizace, návrh datových skladů, competitive intelligence, byznys analýza, cloud computing, datová integrace, atd. Tedy téměř vše, co si lze představit v souvislosti s pojmem řízení dat. Kdo je to Data Scientist? Je to mýtický expert na všechny tyto oblasti, anebo úzce profilovaný specialista? Při zodpovězení této otázky zkusme vyjít z analogie v medicíně. Medicína jako obor je vskutku velmi obsáhlý, nicméně se v něm můžeme setkat se specialisty na jednotlivou problematiku (stomatolog, pediatr, ortoped, ...). Všichni tito specialisté ale musí být vybaveni určitým penzem obecných znalostí z oboru. Podobně tomu bude i v případě datového vědce. Měl by rámcově znát používané technologie, na některé z nich by měl být specialista a současně by měl být schopen absorbovat byznys pozadí v dané předmětné oblasti. Takto chápaný datový vědec by představoval optimálního kandidáta na roli datového stewarda ve světě velkých dat. Současně však tvrdý oříšek pro naše vysoké školství, v němž jsou potřebné znalosti zpravidla roztříštěné mezi různé studijní obory a katedry.
Dalším problémem velkých dat z pohledu Data Governance je určení míry, v níž je nutné úroveň kvality jednotlivých atributů, potažmo celých datových zdrojů, udržovat, respektive míra, při které je ještě datový zdroj použitelný pro daný účel. Není třeba zmiňovat, že z oceánu dostupných dat je třeba uvažovat pouze taková, která mají současné nebo potenciální užití pro daný zpracovávající subjekt, tedy přinášejí současnou nebo potenciální hodnotu. Data bez přínosu představují obdobu shelfware. Pouze generují náklady nikoliv výnosy. Snad proto se v článcích některých autorů můžeme setkat s doplněním původních Gartnerovských „3V“ o čtvrté V, Value. S ohledem na hodnotu jednotlivých zdrojů v kombinaci s realistickým posouzením potenciálu jejich kvality a rizika selhání procesů při využití těchto zdrojů, je nutné nastavit odstupňované úrovně politik v rámci Data Governance. Prioritizace řízení jednotlivých atributů či zdrojů není ničím novým. Pouze se s Big Data stala mnohem komplexnější a složitější. V některých případech může být pro konzumenta informace problematické pochopit, že část dodaných informací může mít menší spolehlivost než část jiná. V mnoha případech se např. můžeme setkat s tvrzením, že data v Hadoop mohou klidně být špatná data. Osobně bych si netroufl takto generalizovat, zvláště ne na bázi použité technologie.
V souvislosti s velkými daty se jeví problematickým i aktuálně populární (a nepopiratelně účelné) sledování „rodokmenu“ dat (Data Lineage). V případě některých zdrojů se však jejich původu jen těžko dopátráme. Absence metadat je jako problém skloňována často např. v souvislosti s Linked Data. V případě tohoto specifického datového zdroje navíc musíme řešit zvýšené riziko výskytu chyb s ohledem na chyby v původním datovém zdroji, chyby vzniklé při transformaci tohoto zdroje do RDF (Resource Description Framework) a chyby vzniklé při prolinkovávání RDF zdrojů.
Velká data narůstají, v souladu se svou definicí se často mění. Jak naložit se stále přibývajícími daty? Více než kdy jindy je nyní z tohoto pohledu důležité řízení životního cyklu informací. Nepotřebná nebo zastaralá data je nutné mazat, aktuálně nepotřebná, ale v budoucnu potenciálně využitelná data je vhodné komprimovat a archivovat.