„The Hive Project“
[1.6.2012] D. PejčochÚvod
V souvislosti s připravovanou hlavní specializací s pracovním názvem „Specialista pro Data Mining“, která je aktuálně projednávána v rámci Katedry znalostního inženýrství na Vysoké škole ekonomické v Praze jsem dostal nápad vytvořit centrální bázi dat používaných v rámci výuky předmětů nově vznikající specializace. Hlavní myšlenkou je zbytečně neduplikovat datové soubory používané při praktické demonstraci metod pro data mining a místo toho soustředit společné úsilí k vybudování báze pokrývající data hlavních vertikál (pojišťovnictví, bankovnictví, telekomunikace, retail, ...) doplněných o externí registry. Tato báze by poskytovala dostatečně velké datové soubory pro účely praktické výuky. Vytvořená báze by současně respektovala principy Data Governance, tj. každý datový zdroj by měl přiřazeného datového stewarda, v jehož odpovědnosti by byl další rozvoj tohoto zdroje a současně udržování požadované míry datové kvality. Na tvorbě a rozvoji datových zdrojů by se podíleli jak vyučující, tak i studenti v rámci bakalářských, diplomových či disertačních prací. Projektu jsem dal pracovní název „The Hive“. Mé záměry jsou splněny zatím do té míry, že výsledky projektu budou využity nejen v rámci výuky mnou přednášeného předmětu 4IZ562 Řízení datové kvality, ale i v rámci bakalářského kurzu 4IZ210 Zpracování informací a znalostí.
Co je The Hive
S pojmem „The Hive“ (Úl) se můžeme setkat v různých souvislostech. Fanoušci seriálu Star Trek si jistě vybaví související pojem „The Hive Mind“ označujícím kolektivní myšlení Borgů, jedné z civilizací, které v tomto seriálu vystupují. Pro další význam pojmu není třeba jít daleko. Název „The Hive“ nesla též podzemní výzkumná laboratoř ve filmu The Resident Evil. V přírodě představuje pojem úl geniální stavbu včel budovanou na základě kolektivní spolupráce. Uvedené historické významy pojmu mají společného jmenovatele právě v díle vzniklém společným úsilím, jehož součástí je každý jedinec. V mých vizích se jedná o datovou základnu budovanou společnými silami vyučujících a studentů, využívanou všemi jejími tvůrci i během jejich dalšího profesního života. Jelikož se jedná o projekt, musí být toto úsilí časově ohraničené. Projekt v pravém slova smyslu začal definicí svého záměru 1.6.2012 a jeho ukončení je předpokládáno k 31.12.2013. Další rozvoj řešení bude realizován buď formou projektů navazujících, anebo mimoprojektovým kontinuálním vývojem.
Základní principy
Základ řešení tvoří znalostí báze specifická pro každou vertikálu (Pojišťovnictví, Bankovnictví, Telekomunikace, Retail, Farmacii, Zpracovatelský průmysl, ...). Její jádro tvoří tzv. kanonický datový model (též společný datový model) skládající se ze standardizovaných atributů (resp. elementů). Na tyto kanonické atributy jsou navěšeny jednak další znalosti jako jsou syntaktická pravidla, standardizační schémata, fonetické algoritmy, seznamy přípustných znaků, seznamy přípustných hodnot, tedy znalosti využitelné primárně pro řízení datové kvality reálných atributů namapovatelných na kanonické elementy, jednak populační charakteristiky, které umožňují vygenerování umělých dat pro danou vertikálu. Vývoj kanonických modelů a získávání na ně navěšených znalostí představuje jednu z náplní předmětu 4IZ562 Řízení datové kvality a navazujících témat diplomových a disertačních prací aktuálně zaváděných do studijního systému ISIS. Jejich rozboru se věnuje zvláštní kapitola tohoto článku a jednak bude jejich aktualizovaný seznam (včetně krátké anotace) k nahlédnutí na mém webu pod odkazem http://www.pejcoch.com/index.php?ID=3&SUBID=2.
Umělá data vygenerovaná na základě báze znalostí (alespoň pro vertikály pojišťovnictví a bankovnictví) budou prozatím sloužit pro účely výuky kurzu 4IZ210 Zpracování informací a znalostí a to zejména pro účely praktické demonstrace jiných úloh získávání znalostí z databází než jsou doposud přednášená asociační pravidla realizovaná nad medicínskými daty získanými z Kardio mise EU. Potenciálně by však mohla být používána i v rámci dalších navazujících kurzů. Pouze na základě jejich širokého využití lze předpokládat postupné zpřesňování charakteristik, na základě nichž budou umělá data generována.
Základ řešení tvoří aplikace CADAQUES (Complex Audit of Data Quality in Enterprise Systems) pro podporu auditu datové kvality a Data Governance vyvíjená v rámci mé disertační práce a open source nástroje firmy Talend používané při výuce kurzu 4IZ562 Řízení datové kvality. Zatímco primárním určením nástrojů firmy Talend v rámci The Hive je vybudování referenční báze klientů, integrace vstupních dat, zajištění aktualizace číselníků a externích registrů a konečně zpřístupnění jednotlivých datových zdrojů formou webových služeb aplikacím třetích stran, role CADAQUES tkví především ve funkcionalitě pro definici kanonického datového modelu, na něj navěšených znalostí a pravidel Data Governance. Postupně by též CADAQUES měla umožňovat realizaci zautomatizovaného auditu datové kvality v souladu s IT Assurance Guide pomocí volání komponent naprogramovaných v jazyce R. Architektura celého řešení je zobrazena na obrázku níže.
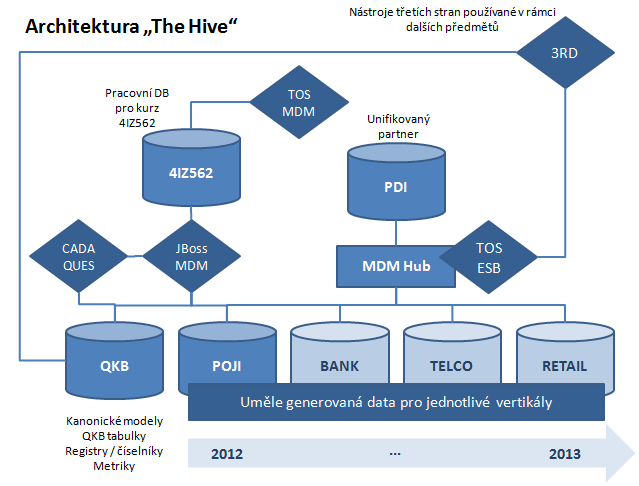
CADAQUES je webová aplikace vytvořená převážně v jazyku PHP. Jejím popisem se zabývá např. článek (Pejčoch, 2012). QKB je označení pro znalostní bázi orientovanou na řízení datové kvality převzaté z terminologie nástroje DataFlux. QKB obsahuje jednotlivé kanonické datové modely a na ně navěšené výše popsané znalosti využitelné pro řízení datové kvality a generování umělých dat. Talend Open Studio (TOS) pro MDM je klientský nástroj pro profilaci dat, datovou integraci a vytváření MDM referenční báze používaný v rámci výuky kurzu 4I562. JBoss MDM představuje serverovou část MDM řešení firmy Talend pro vybudování báze unifikovaného klienta. Tato unifikovaná báze je fyzicky uložena v databázi PDI (Partner Data Integration), jejíž označení reflektuje fakt, že v ní jsou uložena nejen data klientů, ale unifikovaná data osob a firem ve všech rolích, ve kterých se vyskytují v bázích umělých dat pro jednotlivé vertikály (POJI, BANK, TELCO, RETAIL, ...). Nad PDI je vystavena sada služeb vytvořených pomocí nástroje Talend Open Studio for Enterprise Service Bus, umožňujících např. validaci nebo dotaz do jednotlivých bází (unifikovaný partner, jednotlivé vertikály, ...). Označení 3RD představuje ve schématu aplikace třetích stran, tj. klientské nástroje používané v rámci jiných předmětů vyučovaných v rámci katedry (např. Rapid Miner), které by potenciálně mohly využívat data vytvořená v rámci „The Hive“.
Související témata bakalářských, diplomových a disertačních prací
Jak již bylo uvedeno, jedná se o projekt založený na vzájemné spolupráci. Nebylo by prakticky možné vytvořit celou architekturu silami jediného člověka. Scope projektu je proto rozdělen do celé řady témat bakalářských, diplomových a disertačních prací.
Rozvoj aplikace CADAQUES
- Monitoring datové kvality pomocí byznys pravidel. Výstup: vývoj reportingového modulu aplikace v jazyku PHP;
- Rozvoj funkcionality pro profilaci dat. Výstup: vývoj skriptů v jazyku R volaných z aplikace;
- Vývoj modulu pro správu číselníků. Výstup: modul aplikace v jazyku PHP.
Vývoj znalostní báze orientované na řízení datové kvality
- Definice kanonického datového modelu pro vybranou vertikálu (Bankovnictví, Telekomunikace, Retail, ...). Výstup: kanonický datový model jako základ znalostní báze orientované na řízení datové kvality;
- Využití regulárních výrazů pro řízení datové kvality. Výstup: rozvoj knihoven regulárních výrazů v rámci znalostních bází jednotlivých vertikál;
- Využití standardizace při řízení datové kvality. Výstup: standardizační schémata, pravidla pro parsing a syntaktická pravidla v rámci znalostních bází jednotlivých vertikál;
- Využití Bayesovských sítí pro generování umělých dat. Výstup: model pro uchování znalostí o podmíněném rozdělení charakteristik generované populace a generování výběru z této populace.
Rozvoj aplikace Talend Open Studio for MDM
- Rozšiřování funkcionality nástroje TOS MDM. Výstup: vytvoření nových uzlových bodů data flow pomocí jazyka Java a skriptovacího jazyka Groovy;
- Obohacování dat o externí zdroje. Výstup: příprava data flow a webových služeb pro napojování externích registrů a jejich aktualizaci.
Vytváření Master Management Hub
- Návrh a realizace PDI (Partner Data Integration), unifikované báze system-of-record. Výstup: návrh a realizace PDI společné pro použité vertikály (Pojišťovnictví, Bankovnictví, Telekomunikace, Retail, ...);
- Návrh a realizace MDM HUB na platformě TOS ESB (Enterprise Service Bus). Výstup: sada služeb pro dotaz do PDI a externích registrů.
Závěr
Ačkoliv dosud uvedná fakta nasvědčují spíše závěru, že se jedná o projekt realizovaný maximálně v rámci několika předmětů přednášených v rámci Katedry informačního a znalostního inženýrství na VŠE Praha, opak je pravdou. Lze si představit zapojení jak jiných univerzit / kateder, tak i odborníků z praxe. Toto zapojení je dokonce žádoucí. Přispělo by jednak ke zpřesnění znalostí obsažených v QKB, jednak by pomohlo vychovat studenty lépe připravené na praxi (díky byznys znalostem a znalostem datového modelu příslušné vertikály) a konečně, umožnilo by širší rozšíření kanonického datového modelu a QKB do praxe.
Použitá literatura
- PEJČOCH, D. Aplikace pro podporu auditu datové kvality. Sborník prací účastníků vědeckého semináře doktorského studia. Fakulta informatiky a statistiky VŠE. Praha 2012. ISBN 978-80-245-1862-6.